This is the third part of my blog series on fitting the 4-parameter Wiener model with brms. The first part discussed how to set up the data and model. The second part was concerned with (mostly graphical) model diagnostics and the assessment of the adequacy (i.e., the fit) of the model. This third part will inspect the parameter estimates of the model with the goal of determining whether there is any evidence for differences between the conditions. As before, this part is completely self sufficient and can be run without running the code of Parts I or II.
As I promised in the second part of this series of blog posts, the third part did not take another two months to appear. No, this time it took almost eight month. I apologize for this, but we all know the planning fallacy and a lot of more important things got into the way (e.g., teaching).
As this part is relatively long, I will provide a brief overview. The next section contains a short explanation for the way in which we will perform hypothesis testing. This is followed by a short section loading some packages and the fitted model object and giving a small recap of the model. After this comes one relatively long section looking at the drift rate parameters in various ways. Then we will take look at each of the other three parameters in turn. Of especial importance will be the subsection on the non-decision time. As described in more detail below, I believe that this parameter cannot be interpreted. In the end, I give a brief overview of some of the limits of the present model and how it could be improved upon.
Bayesian Hypothesis Testing
The goal of this post is to provide evidence for differences in parameter estimates between conditions. This posts will present different ways to do so. Importantly, different ways of how to produce such evidence is only meant in the technical sense. In statistical terms we will always do basically the same thing: inspect difference distributions resulting from linear combinations of cell-wise posterior distributions of the group-level model parameter estimates. The somewhat technical phrase “linear combinations of cell-wise posterior distributions” often simply means the difference between two distributions. For example, the difference distribution resulting from subtracting the posterior of the speed condition from the posterior of the accuracy condition.
As a reminder, a posterior distribution is the probability distribution of the parameter conditional on data and model (where the latter includes the parameter priors). It answers the question which parameters are likely given our prior knowledge and the data. Therefore, the posterior distribution of the difference answers, for example, which difference values between two conditions are likely or not. With such a difference distribution we can then do two things.
First, we can check whether the x%-highest posterior density (HPD) or credibility interval of this difference distribution includes 0. If 0 is within the 95% HPD interval it could be seen a plausible value. If 0 is outside the 95% interval we could regard it as not plausible enough and would conclude that there is evidence for a difference.
Second, we can evaluate how much of the difference distribution is on one side of 0. If this value is considerably away from 50%, this constitutes evidence for a difference. For example, if all of the posterior samples for a specific difference are larger than zero, this provides considerable evidence that the difference is above 0.
The approach of investigating posterior distributions to gauge differences between conditions is only one approach for hypothesis testing in a Bayesian setting. And, at least in the psychological literature, it is not the most popular one. More specifically, many of the more vocal proponents of Bayesian statistics in the psychological literature advocate hypothesis testing using Bayes factors (e.g., ). One prominent exception to this rule in psychology is maybe John . However, he proposes yet another approach of inference based on posterior distributions as used here. In general, I agree with many of the argument pro Bayes factor, especially in cases as the current one in which all relevant hypothesis or competing models are nested within one large (super) model.
The main difficulty when using Bayes factors is their extreme sensitivity to the parameter priors. In a situation with nested models, this is in principle not such a big problem, because one could use Jeffrey’s default prior approach (e.g., ). have extended this approach to general ANOVA designs (I am sure they were not the first to have this idea, but they were at least the first to popularize this idea in psychology). Quentin Gronau and colleagues have applied it to accumulator models, including the diffusion model. The general idea is to reparameterize the model using effect parameters which are normalized using, for example, the residual variance. For example, for a two sample design parameterize the model using a standardized difference such as Cohen’s d. Then it is comparatively easy and uncontroversial to put a prior on the standardized effect size measure. In the present case, in which the model does not contain a residual variance parameter, one could use the variance estimate of the group-level distribution for each parameter for such a normalization.
Unfortunately, brms does to the best of my knowledge not contain the ability to specify a parameterization and prior distribution in line with Jeffrey’s default Bayes factor. And as far as I remember a discussion I had on this topic with Paul Bürkner some time ago, it is also unlikely brms will ever get this ability. Consequently, I feel that brms is not the right tool for model selection using Bayes factors. Whereas it offers this ability now from a technical side (using our bridgesampling package), it only allows models with an unnormalized parameterization. I believe that such a parameterization is in most cases not appropriate for Bayes factors based model selection as the priors cannot be specified in a ‘default’ manner. Thus, I cannot recommend brms for Bayes factor based model selection at the moment. In sum, the reason for basing our inferences solely on posterior distributions in the present case is practical constraints and not philosophical considerations.
One final word of caution for the psychological readership. Whereas Bayes factors are clearly extremely popular in psychology, this is not the case in many other scientific disciplines. For example, the patron saint of applied Bayesian statistics, Andrew Gelman, is a self-declared opponent of Bayes factors: “I generally hate Bayes factors myself”. As far as I can see, this disagreement comes from the different type of data different people work with. When working with observational (or correlational) data, as Andrew Gelman usually does, tests of the presence of effects (or of nullity) are either a big no-no (e.g., when wanting to do causal inference) or simply not interesting. We know that the real world is full of relationships, especially small ones, between arbitrary things. So getting effects simply by increasing N is just not interesting and estimation is the more interesting approach. In contrast, for experimental data, we often have true null hypothesis and testing of those makes a lot of sense. For example, if Bem was right and there truly were PSI, we could surely exploit this somehow. But as far as we can tell, the effect is truly null. In this case we really need ypothesis testing.
Getting Started
We start with loading some packages for analyzing the posterior. Since the beginning of this series, I have more and more become a fan of the whole tidyverse, so we import it completely. We of course also need brms. As shown below, we will need a few more packages (especially emmeans and tidybayes), but these are only loaded when needed.
library("brms")
library("tidyverse")
theme_set(theme_classic()) # theme for ggplot2
options(digits = 3)
Then we will also need the posterior samples, we can load them in the same way as before from my github page. Note that we neither need the data nor the posterior predictive distribution this time.
tmp <- tempdir()
download.file("https://singmann.github.io/files/brms_wiener_example_fit.rda",
file.path(tmp, "brms_wiener_example_fit.rda"))
load(file.path(tmp, "brms_wiener_example_fit.rda"))
We begin with looking at the group-level posteriors. An overview of their posterior distributions can be obtained using the summary function.
# Estimate Est.Error l-95% CI u-95% CI
# conditionaccuracy:frequencyhigh -2.944 0.1971 -3.345 -2.562
# conditionspeed:frequencyhigh -2.716 0.2135 -3.125 -2.299
# conditionaccuracy:frequencynw_high 2.238 0.1429 1.965 2.511
# conditionspeed:frequencynw_high 1.989 0.1785 1.626 2.332
# bs_conditionaccuracy 1.898 0.1448 1.610 2.186
# bs_conditionspeed 1.357 0.0813 1.200 1.525
# ndt_conditionaccuracy 0.323 0.0173 0.289 0.358
# ndt_conditionspeed 0.262 0.0154 0.232 0.293
# bias_conditionaccuracy 0.471 0.0107 0.449 0.491
# bias_conditionspeed 0.499 0.0127 0.474 0.524
# Warning message:
# There were 7 divergent transitions after warmup. Increasing adapt_delta above 0.8 may help.
# See http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
As a reminder, we have data from a lexical decision task (i.e., participants have to decide whether presented strings are a word or not) and frequency is the factor determining the true status of a string, with high referring to words and nw_high to non-words. Consequently, for the drift rate (the first four rows in the results table) the frequency factor determines the sign of the parameter estimates with the drift rate for words (rows 1 and 2) being clearly negative (i.e., those trials mostly hit the lower boundary for the word decision) and the drift rate for non-words (rows 3 and 4) being clearly positive (i.e., those trials mostly hit the upper boundary for non-word decisions). Furthermore, there could be differences between the drift rates in the accuracy or speed conditions. Specifically, in the speed conditions drift rates seem to be less extreme (i.e., nearer to 0) compared to the accuracy conditions.
The other three parameters, only differ between the condition factor. Given the experimental manipulation of accuracy versus speed condition, we expect differences for the boundary separation, parameters starting with bs_. For the non-decision time, parameters starting with ndt_, there also appears to be a small effect as the 95% only overlap slightly. However, as discussed in detail below, we should be careful in interpreting this difference. Finally, for bias, parameters starting with bias_, there might be a difference or not. Furthermore, at least in the accuracy condition there appears to be a bias for “word” responses.
One way to test differences between conditions is using the hypothesis function in brms. However, I was not able to get it to work with the current model. I suspect the reason for this is the somewhat unconventional parameterizations where each cell gets one parameter (in some sense each cell has its own intercept, but there is no overall intercept). This contrasts with a more “standard” parameterization in which there is one intercept (for either the unweighted means or one of the cells) and the remaining parameters capture the differences between the intercept and the cell means. As a reminder, I chose this unconventional parameterization in the first place to make the specification of the parameters priors easier. Additionally, this is a common parameterization when programming cognitive models by hand.
emmeans and tidybayes: Differences in the Drift Rate
An alternative is to use the great emmeans package by Russel Lenth. I am a huge fan of emmeans and use it all the time when using “normal” statistical models (e.g., ANOVAs, mixed models), independent of whether I use frequentist methods (e.g., via afex) or Bayesian methods (e.g., rstanarm or brms). Unfortunately, it appears as if emmeans at the moment only allows an analysis of the main parameter of the response distribution for models estimated with brms, which in our case is the drift rate. If someone were to extend emmeans to allow using brms models with all parameters, I would be very happy and thankful. In any case, I highly recommend to check out the emmeans vignettes to get an overview of what type of follow-up tests are all possible with this great package.
As I recently learned, emmeans works quite nicely together with tidybayes, a package that enables working with posterior draws within the tidyverse. tidybayes has a surprisingly large package footprint (i.e., it imports quite a lot of other packages) for a package with a comparatively small functionality. I guess this is a consequence of being embedded within the tidyverse. In any case, many of the imported packages are already in the search path thanks to loading the tidyverse above and attaching should not take that long here.
library("emmeans")
library("tidybayes")
We begin with emmeans only to assure ourselves that it works as expected. For this, we get the estimated marginal means plus 95%-highest posterior density (HPD) intervals which match the output of the fixed effects for the estimate of the central tendency (which is the median of the posterior samples in both cases). As a reminder, the fact that the cell estimates match the parameter estimates is of course a consequence of the unusual parameterization which is picked up correctly by emmeans. The lower and upper bounds of the intervals differ slightly between the summary output from brms and emmeans, a consequence of using different ways of calculating the intervals (i.e., quantiles versus HPD intervals).
fit_wiener %>%
emmeans( ~ condition*frequency)
# condition frequency emmean lower.HPD upper.HPD
# accuracy high -2.94 -3.34 -2.56
# speed high -2.72 -3.10 -2.28
# accuracy nw_high 2.24 1.96 2.50
# speed nw_high 1.99 1.64 2.34
#
# HPD interval probability: 0.95
Using HPD Intervals And Histograms
As a first test, we are interested in assessing whether there is evidence for a difference between speed and accuracy conditions for both words (i.e., frequency = high) and non-words (i.e., frequency = nw_high). There are many ways to do this with emmeans one of them is via the by argument and the pairs function.
fit_wiener %>%
emmeans("condition", by = "frequency") %>%
pairs
# frequency = high:
# contrast estimate lower.HPD upper.HPD
# accuracy - speed -0.225 -0.6964 0.256
#
# frequency = nw_high:
# contrast estimate lower.HPD upper.HPD
# accuracy - speed 0.249 -0.0647 0.550
#
# HPD interval probability: 0.95
Here, we do not have a lot of evidence that there is a difference for either stimulus type, as both HPD intervals include 0.
Instead of getting the summary of the distribution via emmeans, we can also use the capabilities of tidybayes and extract the samples in a tidy way. Then we use one of the convenient aggregation functions coming with tidybayes and aggregate the samples based on the same conditioning variable. After trying a few different options, I have the feeling that emmeans‘ hpd.summary() function uses the same approach for calculating HPD intervals as tidybayes, as both results match.
samp1 <- fit_wiener %>%
emmeans("condition", by = "frequency") %>%
pairs %>%
gather_emmeans_draws()
samp1 %>%
median_hdi()
# # A tibble: 2 x 8
# # Groups: contrast [1]
# contrast frequency .value .lower .upper .width .point .interval
# <fct> <fct> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
# 1 accuracy - speed high -0.225 -0.696 0.256 0.95 median hdi
# 2 accuracy - speed nw_high 0.249 -0.0647 0.550 0.95 median hdi
Instead of the median, we can also use the mode as our point estimate. In the present case the differences between both are not large but noticeable for the word stimuli.
samp1 %>%
mode_hdi()
# # A tibble: 2 x 8
# # Groups: contrast [1]
# contrast frequency .value .lower .upper .width .point .interval
# <fct> <fct> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
# 1 accuracy - speed high -0.190 -0.696 0.256 0.95 mode hdi
# 2 accuracy - speed nw_high 0.252 -0.0647 0.550 0.95 mode hdi
Further, we might use a different way for calculating HPD intervals. I have the feeling, Rob Hyndman’s hdrcde package provides the most elaborated set of functions for estimating highest density intervals. Consequently, this is what we use next. Note that the package need to be installed for that.
To use it in a tidy way, we write a short function returning a data.frame in a list. Thus, when called within summarise we get a list-column. Consequently, we have to call unnest to get a nice output.
get_hdi <- function(x, level = 95) {
tmp <- hdrcde::hdr(x, prob = level)
list(data.frame(mode = tmp$mode[1], lower = tmp$hdr[1,1], upper = tmp$hdr[1,2]))
}
samp1 %>%
summarise(hdi = get_hdi(.value)) %>%
unnest
# # A tibble: 2 x 5
# # Groups: contrast [1]
# contrast frequency mode lower upper
# <fct> <fct> <dbl> <dbl> <dbl>
# 1 accuracy - speed high -0.227 -0.712 0.247
# 2 accuracy - speed nw_high 0.249 -0.0616 0.558
The results differ again slightly, but not too much. Perhaps more importantly, there is still no real evidence for a difference in the drift rate between conditions. Even when looking only at 80% HPD intervals there is only evidence for a difference for the non-word stimuli.
samp1 %>%
summarise(hdi = get_hdi(.value, level = 80)) %>%
unnest
# # A tibble: 2 x 5
# # Groups: contrast [1]
# contrast frequency mode lower upper
# <fct> <fct> <dbl> <dbl> <dbl>
# 1 accuracy - speed high -0.212 -0.540 0.0768
# 2 accuracy - speed nw_high 0.246 0.0547 0.442
Because we have the samples in a convenient form, we could now evaluate whether there is any evidence for a drift rate difference between conditions for both, word and non-word stimuli. One problem for this is, however, that the direction of the effect differs between words and non-words. This is a consequence from the fact that word stimuli require a response at the lower decision boundary and non-words a response at the upper boundary. Consequently, we need to multiply the effect with -1 for one of the conditions. After that, we can take the mean of both conditions. We do this via tidyverse magic and also add the number of values that are aggregated in this way to the table. This is just a precaution to make sure that our logic is correct and we always aggregate exactly two values. As the final check shows, this is the case.
samp2 <- samp1 %>%
mutate(val2 = if_else(frequency == "high", -1*.value, .value)) %>%
group_by(contrast, .draw) %>%
summarise(value = mean(val2),
n = n())
all(samp2$n == 2)
# [1] TRUE
We can then investigate the resulting difference distribution. One way to do so is in a graphical manner via a histogram. As recommended by Hadley Wickham, it makes sense to play around with the number of bins a bit until the figure looks good. Given we have quite a large number of samples, 75 bins seemed good to me. With less bins there was not enough granularity, with more bins I felt there were too many small peaks.
ggplot(samp2, aes(value)) +
geom_histogram(bins = 75) +
geom_vline(xintercept = 0)

This shows that, whereas quite a bit of the posterior mass is to the right of 0, a non negligible part is still to the left. So there is some evidence for a difference, but it is still not very strong, even when looking at words and non-words together.
We can also investigate this difference distribution via the HPD intervals. To get a better overview we now look at several intervals sizes:
hdrcde::hdr(samp2$value, prob = c(99, 95, 90, 80, 85, 50))
# $`hdr`
# [,1] [,2]
# 99% -0.1825 0.669
# 95% -0.0669 0.554
# 90% -0.0209 0.505
# 85% 0.0104 0.471
# 80% 0.0333 0.445
# 50% 0.1214 0.340
#
# $mode
# [1] 0.225
#
# $falpha
# 1% 5% 10% 15% 20% 50%
# 0.116 0.476 0.757 0.984 1.161 1.857
This shows that only for the 85% interval and smaller intervals is 0 excluded. Note, you can use hdrcde::hdr.den instead of hdrcde::hdr to get a graphical overview of the output.
Using Bayesian p-values
An approach that requires less arbitrary cutoffs then HPDs (for which we have to define the width) is to calculate the actual proportion of samples below 0:
mean(samp2$value < 0)
# [1] 0.0665
As explained above, if this proportion would be small, this would constitute evidence for a difference. Here, the proportion of samples below 0 is .067. Unfortunately, .067 is a bit above the magical cutoff of .05, which is universally accepted as delineating small from big numbers, or perhaps more appropriately, likely from unlikely probabilities.
Let us look at such a proportion a bit more in depth. If two posterior distributions are lying exactly on top of each other, the resulting difference distribution is centered on 0 and exactly 50% of the difference distribution would be on either side of 0. Thus, a proportion of 50% corresponds to the least evidence for a difference, or alternatively, to the strongest evidence for an absence of a difference. One further consequence is that both, values near 0 and values near 1, are indicative of a difference, albeit in different directions. To make interpretation of these proportions easier, I suggest to always calculate them in such a way that small values represent evidence for a difference (e.g., by subtracting the proportion from 1 if it is above .5).
But what does this proportion tell us exactly? It represents the probability that there is a difference in a specific direction. Thus, it represents one-sided evidence for a difference. In contrast, for a 95% HPD we remove 2.5% from each sides of the difference distribution. To ensure this proportion has the same two-sided property as our HPD intervals, we need to multiply it by 2. A further benefit of this multiplication is that it stretches the range to the whole probability scale (i.e., from 0 to 1).
Thus, the resulting value is a probability (i.e., ranging from 0 to 1), with values near zero denoting evidence for a difference, and values near one provide some evidence against a difference. Thus, in contrast to a classical p-value it is a continuous measure of evidence for (when near 0) or against (when near 1) a difference between the parameter estimates. Given its superficial similarity with classical p-values (i.e., low values are seen as evidence for a difference), we could call this it a version of a Bayesian p-value or pB for short. In the present case we could say: The pB value for a difference between speed and accuracy conditions in drift rate across word and non-word stimuli is .13, indicating that the evidence for a difference is at best weak.
Bayesian p-values of course allows us to misuse them in the same way that we can misuse classical p-values. For example, by introducing arbitrary cutoff values, such as at .05. Imagine for a second that we are interested in testing whether there are differences in the absolute amount of evidence as measured via drift rate for any of the four cells of the design (I am not suggesting that is particularly sensible). For this, we would have to transform the posterior for all drift rates onto the same side (note, we do not want to take the absolute values as we still want to retain the information of switching from positive to negative drift rates or the other way around). For example, by multiplying the drift rate for words by -1. We do so and then inspect the cell means.
samp3 <- fit_wiener %>%
emmeans( ~ condition*frequency) %>%
gather_emmeans_draws() %>%
mutate(.value = if_else(frequency == "high", -1 * .value, .value),
intera = paste(condition, frequency, sep = "."))
samp3 %>%
mode_hdi(.value)
# # A tibble: 4 x 8
# # Groups: condition [2]
# condition frequency .value .lower .upper .width .point .interval
# <fct> <fct> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
# 1 accuracy high 2.97 2.56 3.34 0.95 mode hdi
# 2 accuracy nw_high 2.25 1.96 2.50 0.95 mode hdi
# 3 speed high 2.76 2.28 3.10 0.95 mode hdi
# 4 speed nw_high 2.00 1.64 2.34 0.95 mode hdi
Inspection of the four cell means suggests that drift rate values for words are larger then the values for non-words.
To get an overview of all pairwise differences using an arbitrary cut-off value, I have written two functions that returns a compact letter display of all pairwise comparisons. The functions require the data in the wide format, with each column representing the draws for one parameter. Note that the compact letter display is calculated via another package, multcompView, which needs to be installed before using these functions.
get_p_matrix <- function(df, only_low = TRUE) {
# pre-define matrix
out <- matrix(-1, nrow = ncol(df), ncol = ncol(df), dimnames = list(colnames(df), colnames(df)))
for (i in seq_len(ncol(df))) {
for (j in seq_len(ncol(df))) {
out[i, j] <- mean(df[,i] < df[,j])
}
}
if (only_low) out[out > .5] <- 1- out[out > .5]
out
}
cld_pmatrix <- function(model, pars, level = 0.05) {
p_matrix <- get_p_matrix(model)
lp_matrix <- (p_matrix < (level/2) | p_matrix > (1-(level/2)))
cld <- multcompView::multcompLetters(lp_matrix)$Letters
cld
}
samp3 %>%
ungroup() %>% ## to get rid of unneeded columns
select(.value, intera, .draw) %>%
spread(intera, .value) %>%
select(-.draw) %>% ## we need to get rid of all columns not containing draws
cld_pmatrix()
# accuracy.high accuracy.nw_high speed.high speed.nw_high
# "a" "b" "a" "b"
In a compact letter display, conditions that share a common letter do not differ according to the criterion. Conditions that do not share a common letter do differ according to the criterion. Here, the compact letter display is not super informative and just recovers what we have seen above. The drift rates for the words form one group and the drift rates for the non-words form another group. In cases with more conditions or more complicated difference pattern compact letter displays can be quite informative.
We could have also used the functionality of tidybayes to inspect all pairwise comparisons. Note that it is important to use ungroup before invoking the compare_levels function. Otherwise we get an error that is difficult to understand (the grouping appears to be a consequence of using emmeans).
samp3 %>%
ungroup %>%
compare_levels(.value, by = intera) %>%
mode_hdi()
# # A tibble: 6 x 7
# intera .value .lower .upper .width .point .interval
# <fct> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
# 1 accuracy.nw_high - accuracy.high -0.715 -1.09 -0.351 0.95 mode hdi
# 2 speed.high - accuracy.high -0.190 -0.696 0.256 0.95 mode hdi
# 3 speed.nw_high - accuracy.high -0.946 -1.46 -0.526 0.95 mode hdi
# 4 speed.high - accuracy.nw_high 0.488 0.0879 0.876 0.95 mode hdi
# 5 speed.nw_high - accuracy.nw_high -0.252 -0.550 0.0647 0.95 mode hdi
# 6 speed.nw_high - speed.high -0.741 -1.12 -0.309 0.95 mode hdi
Differences in Other Parameters
As discussed above, to look at the differences in the other parameter we apparently cannot use emmeans anymore. Luckily, tidybayes still offers the possibility to extract the posterior samples in a tidy way using either gather_draws or spread_draws. It appears that for either of those you need to pass the specific variable names you want to extract. We get them via get_variables:
get_variables(fit_wiener)[1:10]
# [1] "b_conditionaccuracy:frequencyhigh" "b_conditionspeed:frequencyhigh"
# [3] "b_conditionaccuracy:frequencynw_high" "b_conditionspeed:frequencynw_high"
# [5] "b_bs_conditionaccuracy" "b_bs_conditionspeed"
# [7] "b_ndt_conditionaccuracy" "b_ndt_conditionspeed"
# [9] "b_bias_conditionaccuracy" "b_bias_conditionspeed"
Boundary Separation
We will use spread_draws to analyze the boundary separation. First we extract the draws and then immediately calculate the difference distribution between both.
samp_bs <- fit_wiener %>%
spread_draws(b_bs_conditionaccuracy, b_bs_conditionspeed) %>%
mutate(bs_diff = b_bs_conditionaccuracy - b_bs_conditionspeed)
samp_bs
# # A tibble: 2,000 x 6
# .chain .iteration .draw b_bs_conditionaccuracy b_bs_conditionspeed bs_diff
# <int> <int> <int> <dbl> <dbl> <dbl>
# 1 1 1 1 1.73 1.48 0.250
# 2 1 2 2 1.82 1.41 0.411
# 3 1 3 3 1.80 1.28 0.514
# 4 1 4 4 1.85 1.42 0.424
# 5 1 5 5 1.86 1.37 0.493
# 6 1 6 6 1.81 1.36 0.450
# 7 1 7 7 1.67 1.34 0.322
# 8 1 8 8 1.90 1.47 0.424
# 9 1 9 9 1.99 1.20 0.790
# 10 1 10 10 1.76 1.19 0.569
# # ... with 1,990 more rows
Now we can of course use the same tools as above. For example, look at the histogram. Here, I again chose 75 bins.
samp_bs %>%
ggplot(aes(bs_diff)) +
geom_histogram(bins = 75) +
geom_vline(xintercept = 0)

The histogram reveals pretty convincing evidence for a difference. It appears as if only two samples are below 0. We confirm this suspicion and then calculate the Bayesian p-value. As it turns out, is is also extremely small.
sum(samp_bs$bs_diff < 0)
# [1] 2
mean(samp_bs$bs_diff < 0) *2
# [1] 0.002
All in all we can be pretty confident that manipulating speed versus accuracy conditions affects the boundary separation in the current data set. Exactly as expected.
Non-Decision Time
For assessing differences in the non-decision time, we use gather_draws. One benefit of this function compared to spread_draws is that it makes it easy to obtain the marginal estimates. As already said above, the HPD interval overlap only very little suggesting that there is a difference between the conditions. We save the resulting marginal estimates for later in a new data.frame called ndt_mean.
samp_ndt <- fit_wiener %>%
gather_draws(b_ndt_conditionaccuracy, b_ndt_conditionspeed)
(ndt_mean <- samp_ndt %>%
median_hdi())
# # A tibble: 2 x 7
# .variable .value .lower .upper .width .point .interval
# <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
# 1 b_ndt_conditionaccuracy 0.323 0.293 0.362 0.95 median hdi
# 2 b_ndt_conditionspeed 0.262 0.235 0.295 0.95 median hdi
To evaluate the difference, the easiest approach to me seems again to spread the two variables across rows and then calculate the difference (i.e., similar to starting with spread_draws in the first place). We can then again plot the resulting difference distribution.
samp_ndt2 <- samp_ndt %>%
spread(.variable, .value) %>%
mutate(ndt_diff = b_ndt_conditionaccuracy - b_ndt_conditionspeed)
samp_ndt2 %>%
ggplot(aes(ndt_diff)) +
geom_histogram(bins = 75) +
geom_vline(xintercept = 0)

As previously speculated, there appears to be strong evidence for a difference. We can further confirm this via the Bayesian p-value:
mean(samp_ndt2$ndt_diff < 0) * 2
# [1] 0.005
So far this looks as if we found another clear difference in parameter estimates due to the manipulation. But this conclusion would be premature. In fact, investigating the non-decision time from the 4-parameter Wiener model estimated in this way is completely misleading. Instead of capturing a meaningful feature of the response time distribution, the non-decision time parameter is only sensitive to very few data points. Specifically, the non-decision time basically only reflects a specific feature of the distribution of minimum response times per participant and per condition or cell for which it is estimated. I will demonstrate this in the following for our example data.
We first need to load the data in the same manner as in the previous posts. We then calculate the minimum RTs per participant and condition.
data(speed_acc, package = "rtdists")
speed_acc <- droplevels(speed_acc[!speed_acc$censor,]) # remove extreme RTs
speed_acc <- droplevels(speed_acc[ speed_acc$frequency %in%
c("high", "nw_high"),])
min_val <- speed_acc %>%
group_by(condition, id) %>%
summarise(min = min(rt))
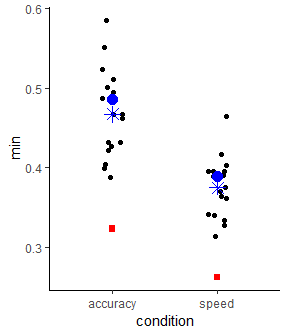
To investigate the problem, we want to graphically compare the the distribution of minimum RTs with the estimates for the non-decision time. For this, we need to add a condition column with matching condition names to the ndt_mean data.frame created above. Then, we can plot both into the same plot. We also add several summary statistics regarding the distribution of individual minimum RTs. Specifically, the black points show the individual minimum RTs for each of the two conditions; the blue + shows the median and the blue x the mean of the individual minimum RTs; the blue circle shows the midpoint between the largest and smallest value of the minimum RT distributions; the red square shows the point estimate of the non-decision time parameter with corresponding 95% HPD intervals.
ndt_mean$condition <- c("accuracy", "speed")
ggplot(min_val, aes(x = condition, y = min)) +
geom_jitter(width = 0.1) +
geom_pointrange(data = ndt_mean,
aes(y = .value, ymin = .lower, ymax = .upper),
shape = 15, size = 1, color = "red") +
stat_summary(col = "blue", size = 3.5, shape = 3,
fun.y = "median", geom = "point") +
stat_summary(col = "blue", size = 3.5, shape = 4,
fun.y = "mean", geom = "point") +
stat_summary(col = "blue", size = 3.5, shape = 16,
fun.y = function(x) (min(x) + max(x))/2,
geom = "point")

What this graph rather impressively shows is that the estimate of the non-decision time almost perfectly matches the midpoint between largest and smallest minimum RT (i.e., the blue dot). Let us put this in perspective by comparing the number of minimum data points (i.e., the number of participants) to the number of total data points.
speed_acc %>%
group_by(condition) %>%
summarise(n())
# # A tibble: 2 x 2
# condition `n()`
# <fct> <int>
# 1 accuracy 5221
# 2 speed 5241
length(unique(speed_acc$id))
# [1] 17
17 / 5000
# [1] 0.0034
This shows that the non-decision time parameter, one of only four model parameters, is essentially completely determined by less than .5% of the data. If any of these minimum RTs is an outlier (which at least in the accuracy condition seems likely) a single response time can have an immense influence on the parameter estimate. In other words, it can hardly be assumed that with the current implementation the non-decision time parameter reflects an actual latent process. Instead, it simply reflects the midpoint between smallest and largest minimum RT per participant and condition, slightly weighted toward the mass of the distribution of minimum RTs. This parameter estimate should not be used to draw substantive conclusions.
In the present case, this confound does not appear to be too consequential. If only one of the data points in the accuracy condition is an outlier and the other data points are faithful representatives of the leading edge of the response time distribution (which is essentially what the non-decision time is supposed to capture), the current parameter estimates underestimate the true difference. Using a more robust ad-hoc measure of the leading edge, specifically the 10% trimmed mean of the 40 fastest RTs per participant and condition plotted below, further supports this conclusion. This graph also does not contain any clear outliers anymore. For reference, the non-decision time estimates are still included. Nevertheless, having a parameter be essentially driven by very few data points seems completely at odds with the general idea of cognitive modeling and the interpretation of non-decision times obtained with such a model cannot be recommended.
min_val2 <- speed_acc %>%
group_by(condition, id) %>%
summarise(min = mean(sort(rt)[1:40], trim = 0.1))
ggplot(min_val2, aes(x = condition, y = min)) +
geom_jitter(width = 0.1) +
stat_summary(col = "blue", size = 3.5, shape = 3,
fun.y = "median", geom = "point") +
stat_summary(col = "blue", size = 3.5, shape = 4,
fun.y = "mean", geom = "point") +
stat_summary(col = "blue", size = 3.5, shape = 16,
fun.y = function(x) (min(x) + max(x))/2,
geom = "point") +
geom_point(data = ndt_mean, aes(y = .value), shape = 15,
size = 2, color = "red")
It is important to note that this confound does not hold for all implementations of the diffusion model, but is specific to the 4-parameter Wiener model as implemented here. There are solutions for avoiding this problem, two of which I want to list here. First, one could add across trial variability in the non-decision time. This variability is often assumed to come a uniform distribution which can capture outliers at the leading edge of the response time distribution. Second, instead of only fitting a diffusion model one could assume that some of the responses are contaminants coming from a different process, for example random responses from a uniform distribution ranging from the absolute minimum to maximum RT. Technically, this would consitute a mixture model between the diffusion process and a uniform distribution with either a free or fixed mixture/contamination rate (e.g., ). It should be relatively easy to implement such a mixture model via a custom_family in brms and I hope to find the time to do that at some later point.
I am of course not the first one to discover this behavior of the 4-parameter Wiener model (see e.g., ). However, this problem seems especially prevalent in a Bayesian setting as the 4-parameter model variant is readily available and model variants appropriately dealing with this problem are not. Some time ago I asked Chris Donkin and Greg Cox what they thought would be the best way to address this issue and the one thing I remember from this discussion was Chris’ remark that, when he uses the 4-parameter Wiener model, he simply ignores the non-decision time parameter. That still seems like the best course of action to me.
I hope there are not too many papers out there that use the 4-parameter model in such a way and interpret differences in the non-decision time parameter. If you know of one, I would be interested to learn about it. Either write me a mail or post it in the comments below.
Starting Point / Bias
Finally, we can take a look at the starting point or bias. We do this again using spread_draws and then plot the resulting difference distribution.
samp_bias <- fit_wiener %>%
spread_draws(b_bias_conditionaccuracy, b_bias_conditionspeed) %>%
mutate(bias_diff = b_bias_conditionaccuracy - b_bias_conditionspeed)
samp_bias %>%
ggplot(aes(bias_diff)) +
geom_histogram(bins = 100) +
geom_vline(xintercept = 0)

The difference distributions suggests there might be a difference. Consequently, we calculate the Bayesian p-value next. Note that we calculate the difference in the other direction this time so that evidence for a difference is represented by small values.
mean(samp_bias$bias_diff > 0) *2
# [1] 0.046
We get lucky and our Bayesian p-value is just below .05, encouraging us to believe that the difference is real. To round this up, we again take a look at the estimates:
fit_wiener %>%
gather_draws(b_bias_conditionaccuracy, b_bias_conditionspeed) %>%
summarise(hdi = get_hdi(.value, level = 80)) %>%
unnest
# # A tibble: 2 x 4
# .variable mode lower upper
# <chr> <dbl> <dbl> <dbl>
# 1 b_bias_conditionaccuracy 0.470 0.457 0.484
# 2 b_bias_conditionspeed 0.498 0.484 0.516
Together with the evidence for a difference we can now postulate in a more confident manner that for the accuracy condition there is a bias toward the lower boundary and the “word” responses, whereas evidence accumulation starts unbiased in the speed condition.
Closing Words
This third part wraps up a the most important steps in a diffusion model analysis with brms. Part I shows how to setup the model, Part II shows how to evaluate the adequacy of the model, and the present Part III shows how to inspect the parameter and test hypotheses about them.
As I have mentioned quite a bit throughout these parts, the model used here is not the full diffusion model, but the 4-parameter Wiener model. Whereas this makes estimation possible in the first place, it comes with a few problems. One of them was discussed at length in the present part. The estimate of the non-decision time parameter essentially captures a feature of the distribution of minimum RTs. If these are contaminated by responses that cannot be assumed to come from the same process as the other responses (which I believe a priori to be quite likely), the estimate becomes rather meaningless. My take away from this is that I would not interpret these estimates at all. I feel that the dangers outweigh the benefits by far.
Another feature of the 4-parameter Wiener model is that, in the absence of a bias for any of the response options, it predicts equal mean response times for correct and error responses. This is perhaps the main theoretical constraint which has led to the development of many of the more highly parameterized model variants, such as the full (i.e., 7-parameter) diffusion model. An overview of this issue can, for example, be found in . They write (p. 335):
Depending on the experimental manipulation, RTs for errors are sometimes shorter than RTs for correct responses, sometimes longer, and sometimes there is a crossover in which errors are slower than correct responses when accuracy is low and faster than correct responses when accuracy is high. The models must be capable of capturing all these aspects of a data set.
For the present data we find a specific pattern that is often seen as typical. As shown below, error RTs are quite a bit slower than correct RTs in the accuracy condition. This effect cannot be found in the speed condition where, if anything, error RTs are faster than correct RTs.
speed_acc %>%
mutate(correct = stim_cat == response) %>%
group_by(condition, correct, id) %>%
summarise(mean = mean(rt),
se = mean(rt)/sqrt(n())) %>%
summarise(mean = mean(mean),
se = mean(se))
# # A tibble: 4 x 4
# # Groups: condition [?]
# condition correct mean se
# <fct> <lgl> <dbl> <dbl>
# 1 accuracy FALSE 0.751 0.339
# 2 accuracy TRUE 0.693 0.0409
# 3 speed FALSE 0.491 0.103
# 4 speed TRUE 0.513 0.0314
Given this difference in the relative speeds of correct and error responses in the accuracy condition, it may seem unsurprising that the accuracy condition is also the one in which we have a measurable bias. Specifically, a bias towards the word responses. However, as can be seen by adding stim_cat into the group_by call above, the difference in the relative error rate is particularly strong for non-words where a bias toward words should lead to faster errors. Thus, it appears that some of the more subtle effects in the data are not fully accounted for in the current model variant.
The canonical way for dealing with differences in the relative speed of errors in diffusion modeling is via across-trial variabilities in the model parameters (see ). Variability in the starting point (introduced by Laming, 1968) allows errors RTs to be faster than correct RTs. Variability in the drift rate (introduced by ) allows error RTs to be slower than correct RTs. (As discussed above, variability in the non-decision time allows its parameter estimates to be less influenced by contaminates or individual outliers.) However, as described below, introducing these variabilities in a Bayesian framework comes with its own problems. Furthermore, there is a recent discussion of the value of these variabilities from a measurement standpoint.
Possible Future Extensions
Whereas this series comes to an end here, there are a few further things that seem either important, interesting, or viable. Maybe I will have some time in the future to talk about these as well, but I suggest to not expect those soon.
- One important thing we have not yet looked at is the estimates of the group-level parameters (i.e., standard deviations and correlations). They may contain important information about the specific data set and research question, but also about the tradeoffs of the model parameters.
-
Replacing the pure Wiener process with a mixture between a Wiener and a uniform distribution to be able to interpret the non-decision time. As written above, this should be doable with a custom_family in brms.
-
As described above, one of the driving forces for modern response time models, such as the 7-parameter diffusion model, were differences in the relative speed of error and correct RTs. These are usually explained via variabilities in the model parameters. One relatively straight forward way to implement these variabilities in a Bayesian setting would be via the hierarchical structure. For example, each participant gets a by-trial random intercept for the drift rate, + (0+id||trial) (the double bar notation should ensure that these are uncorrelated across participants). Whereas this sounds conceptually simple, I doubt such a model will converge in a reasonable timeframe. Furthermore, as shown by , a model in which the shape of the variability distribution is essentially unconstrained (as is the case when only constraining it via the prior as suggested here) is not testable. The model becomes unfalsifiable as it can predict any data pattern. Given the importance of this approach from a theoretical point of view it nevertheless seems to be an extremely important angle to explore.
-
Fitting the Wiener model takes quite a lot of time. It would be interesting to compare the fit using full Bayesian inference (i.e., sampling as done here) with variational Bayes (i.e., parametric approximation of the posterior), which is also implemented in Stan. I expect that it does not work that well, but the comparison would still be interesting. Recently, diagnostics for variational Bayes were introduced.
-
The diffusion model is of course only one model for response time data. A popular alternative is the LBA. I know there are some implementations in Stan out there, so if they could be accessed via brms, this would be quite interesting.
The RMarkdown file for this post is available here.
References
{881472:8DDMVQM7},{881472:6KZWXEP9};{881472:298PA4EJ};{881472:WIJMV4QQ};{881472:45ZMK47X};{881472:ZHP5HS3A};{881472:ZHP5HS3A};{881472:WMSI9W72};{881472:WMSI9W72},{881472:QQ2QRTIF};{881472:3CKVQRZ5};{881472:ZXW7LMEE}
apa
default
asc
0
708
%7B%22status%22%3A%22success%22%2C%22updateneeded%22%3Afalse%2C%22instance%22%3Afalse%2C%22meta%22%3A%7B%22request_last%22%3A2350%2C%22request_next%22%3A50%2C%22used_cache%22%3Atrue%7D%2C%22data%22%3A%5B%7B%22key%22%3A%22JML5TCNG%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Baumann%20et%20al.%22%2C%22parsedDate%22%3A%222020-06-09%22%2C%22numChildren%22%3A4%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BBaumann%2C%20C.%2C%20Singmann%2C%20H.%2C%20Gershman%2C%20S.%20J.%2C%20%26amp%3B%20Helversen%2C%20B.%20von.%20%282020%29.%20A%20linear%20threshold%20model%20for%20optimal%20stopping%20behavior.%20%26lt%3Bi%26gt%3BProceedings%20of%20the%20National%20Academy%20of%20Sciences%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B117%26lt%3B%5C%2Fi%26gt%3B%2823%29%2C%2012750%26%23x2013%3B12755.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1073%5C%2Fpnas.2002312117%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1073%5C%2Fpnas.2002312117%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22A%20linear%20threshold%20model%20for%20optimal%20stopping%20behavior%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Christiane%22%2C%22lastName%22%3A%22Baumann%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Henrik%22%2C%22lastName%22%3A%22Singmann%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Samuel%20J.%22%2C%22lastName%22%3A%22Gershman%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Bettina%20von%22%2C%22lastName%22%3A%22Helversen%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222020%5C%2F06%5C%2F09%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1073%5C%2Fpnas.2002312117%22%2C%22ISSN%22%3A%220027-8424%2C%201091-6490%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fwww.pnas.org%5C%2Fcontent%5C%2F117%5C%2F23%5C%2F12750%22%2C%22collections%22%3A%5B%22IFJ5FWUK%22%5D%2C%22dateModified%22%3A%222020-07-09T13%3A21%3A17Z%22%7D%7D%2C%7B%22key%22%3A%22RZIVHHUA%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Merkle%20and%20Wang%22%2C%22parsedDate%22%3A%222018-02-01%22%2C%22numChildren%22%3A3%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BMerkle%2C%20E.%20C.%2C%20%26amp%3B%20Wang%2C%20T.%20%282018%29.%20Bayesian%20latent%20variable%20models%20for%20the%20analysis%20of%20experimental%20psychology%20data.%20%26lt%3Bi%26gt%3BPsychonomic%20Bulletin%20%26amp%3B%20Review%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B25%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%20256%26%23x2013%3B270.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13423-016-1016-7%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13423-016-1016-7%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Bayesian%20latent%20variable%20models%20for%20the%20analysis%20of%20experimental%20psychology%20data%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Edgar%20C.%22%2C%22lastName%22%3A%22Merkle%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Ting%22%2C%22lastName%22%3A%22Wang%22%7D%5D%2C%22abstractNote%22%3A%22In%20this%20paper%2C%20we%20address%20the%20use%20of%20Bayesian%20factor%20analysis%20and%20structural%20equation%20models%20to%20draw%20inferences%20from%20experimental%20psychology%20data.%20While%20such%20application%20is%20non-standard%2C%20the%20models%20are%20generally%20useful%20for%20the%20unified%20analysis%20of%20multivariate%20data%20that%20stem%20from%2C%20e.g.%2C%20subjects%5Cu2019%20responses%20to%20multiple%20experimental%20stimuli.%20We%20first%20review%20the%20models%20and%20the%20parameter%20identification%20issues%20inherent%20in%20the%20models.%20We%20then%20provide%20details%20on%20model%20estimation%20via%20JAGS%20and%20on%20Bayes%20factor%20estimation.%20Finally%2C%20we%20use%20the%20models%20to%20re-analyze%20experimental%20data%20on%20risky%20choice%2C%20comparing%20the%20approach%20to%20simpler%2C%20alternative%20methods.%22%2C%22date%22%3A%222018-02-01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.3758%5C%2Fs13423-016-1016-7%22%2C%22ISSN%22%3A%221531-5320%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13423-016-1016-7%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-07-09T13%3A20%3A54Z%22%7D%7D%2C%7B%22key%22%3A%22G73BS2AL%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Overstall%20and%20Forster%22%2C%22parsedDate%22%3A%222010-12-01%22%2C%22numChildren%22%3A2%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BOverstall%2C%20A.%20M.%2C%20%26amp%3B%20Forster%2C%20J.%20J.%20%282010%29.%20Default%20Bayesian%20model%20determination%20methods%20for%20generalised%20linear%20mixed%20models.%20%26lt%3Bi%26gt%3BComputational%20Statistics%20%26amp%3B%20Data%20Analysis%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B54%26lt%3B%5C%2Fi%26gt%3B%2812%29%2C%203269%26%23x2013%3B3288.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.csda.2010.03.008%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.csda.2010.03.008%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Default%20Bayesian%20model%20determination%20methods%20for%20generalised%20linear%20mixed%20models%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Antony%20M.%22%2C%22lastName%22%3A%22Overstall%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Jonathan%20J.%22%2C%22lastName%22%3A%22Forster%22%7D%5D%2C%22abstractNote%22%3A%22A%20default%20strategy%20for%20fully%20Bayesian%20model%20determination%20for%20generalised%20linear%20mixed%20models%20%28GLMMs%29%20is%20considered%20which%20addresses%20the%20two%20key%20issues%20of%20default%20prior%20specification%20and%20computation.%20In%20particular%2C%20the%20concept%20of%20unit-information%20priors%20is%20extended%20to%20the%20parameters%20of%20a%20GLMM.%20A%20combination%20of%20Markov%20chain%20Monte%20Carlo%20%28MCMC%29%20and%20Laplace%20approximations%20is%20used%20to%20compute%20approximations%20to%20the%20posterior%20model%20probabilities%20to%20find%20a%20subset%20of%20models%20with%20high%20posterior%20model%20probability.%20Bridge%20sampling%20is%20then%20used%20on%20the%20models%20in%20this%20subset%20to%20approximate%20the%20posterior%20model%20probabilities%20more%20accurately.%20The%20strategy%20is%20applied%20to%20four%20examples.%22%2C%22date%22%3A%22December%201%2C%202010%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1016%5C%2Fj.csda.2010.03.008%22%2C%22ISSN%22%3A%220167-9473%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.sciencedirect.com%5C%2Fscience%5C%2Farticle%5C%2Fpii%5C%2FS0167947310001106%22%2C%22collections%22%3A%5B%2232HV3NV5%22%5D%2C%22dateModified%22%3A%222020-07-09T13%3A20%3A39Z%22%7D%7D%2C%7B%22key%22%3A%2238I8ZEFY%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Llorente%20et%20al.%22%2C%22parsedDate%22%3A%222020-05-17%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BLlorente%2C%20F.%2C%20Martino%2C%20L.%2C%20Delgado%2C%20D.%2C%20%26amp%3B%20Lopez-Santiago%2C%20J.%20%282020%29.%20Marginal%20likelihood%20computation%20for%20model%20selection%20and%20hypothesis%20testing%3A%20an%20extensive%20review.%20%26lt%3Bi%26gt%3BArXiv%3A2005.08334%20%5BCs%2C%20Stat%5D%26lt%3B%5C%2Fi%26gt%3B.%20Retrieved%20from%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttp%3A%5C%2F%5C%2Farxiv.org%5C%2Fabs%5C%2F2005.08334%26%23039%3B%26gt%3Bhttp%3A%5C%2F%5C%2Farxiv.org%5C%2Fabs%5C%2F2005.08334%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Marginal%20likelihood%20computation%20for%20model%20selection%20and%20hypothesis%20testing%3A%20an%20extensive%20review%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Fernando%22%2C%22lastName%22%3A%22Llorente%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Luca%22%2C%22lastName%22%3A%22Martino%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22David%22%2C%22lastName%22%3A%22Delgado%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Javier%22%2C%22lastName%22%3A%22Lopez-Santiago%22%7D%5D%2C%22abstractNote%22%3A%22This%20is%20an%20up-to-date%20introduction%20to%2C%20and%20overview%20of%2C%20marginal%20likelihood%20computation%20for%20model%20selection%20and%20hypothesis%20testing.%20Computing%20normalizing%20constants%20of%20probability%20models%20%28or%20ratio%20of%20constants%29%20is%20a%20fundamental%20issue%20in%20many%20applications%20in%20statistics%2C%20applied%20mathematics%2C%20signal%20processing%20and%20machine%20learning.%20This%20article%20provides%20a%20comprehensive%20study%20of%20the%20state-of-the-art%20of%20the%20topic.%20We%20highlight%20limitations%2C%20benefits%2C%20connections%20and%20differences%20among%20the%20different%20techniques.%20Problems%20and%20possible%20solutions%20with%20the%20use%20of%20improper%20priors%20are%20also%20described.%20Some%20of%20the%20most%20relevant%20methodologies%20are%20compared%20through%20theoretical%20comparisons%20and%20numerical%20experiments.%22%2C%22date%22%3A%222020-05-17%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Farxiv.org%5C%2Fabs%5C%2F2005.08334%22%2C%22collections%22%3A%5B%2232HV3NV5%22%5D%2C%22dateModified%22%3A%222020-07-06T15%3A23%3A31Z%22%7D%7D%2C%7B%22key%22%3A%22DCGXG7FJ%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Duersch%20et%20al.%22%2C%22parsedDate%22%3A%222020%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BDuersch%2C%20P.%2C%20Lambrecht%2C%20M.%2C%20%26amp%3B%20Oechssler%2C%20J.%20%282020%29.%20Measuring%20skill%20and%20chance%20in%20games.%20%26lt%3Bi%26gt%3BEuropean%20Economic%20Review%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B127%26lt%3B%5C%2Fi%26gt%3B%2C%20103472.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.euroecorev.2020.103472%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.euroecorev.2020.103472%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Measuring%20skill%20and%20chance%20in%20games%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Peter%22%2C%22lastName%22%3A%22Duersch%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Marco%22%2C%22lastName%22%3A%22Lambrecht%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Joerg%22%2C%22lastName%22%3A%22Oechssler%22%7D%5D%2C%22abstractNote%22%3A%22Online%20and%20o%5Cufb04ine%20gaming%20has%20become%20a%20multi-billion%20dollar%20industry.%20However%2C%20games%20of%20chance%20are%20prohibited%20or%20tightly%20regulated%20in%20many%20jurisdictions.%20Thus%2C%20the%20question%20whether%20a%20game%20predominantly%20depends%20on%20skill%20or%20chance%20has%20important%20legal%20and%20regulatory%20implications.%20In%20this%20paper%2C%20we%20suggest%20a%20new%20empirical%20criterion%20for%20distinguishing%20games%20of%20skill%20from%20games%20of%20chance%3A%20All%20players%20are%20ranked%20according%20to%20a%20%5Cu201cbest-%5Cufb01t%5Cu201d%20Elo%20algorithm.%20The%20wider%20the%20distribution%20of%20player%20ratings%20are%20in%20a%20game%2C%20the%20more%20important%20is%20the%20role%20of%20skill.%20Most%20importantly%2C%20we%20provide%20a%20new%20benchmark%20%28%5Cu201c50%25chess%5Cu201d%29%20that%20allows%20to%20decide%20whether%20games%20predominantly%20%28more%20than%2050%25%29%20depend%20on%20chance%2C%20as%20this%20criterion%20is%20often%20used%20by%20courts.%20We%20apply%20the%20method%20to%20large%20datasets%20of%20various%20two-player%20games%20%28e.g.%20chess%2C%20poker%2C%20backgammon%2C%20tetris%29.%20Our%20%5Cufb01ndings%20indicate%20that%20most%20popular%20online%20games%2C%20including%20poker%2C%20are%20below%20the%20threshold%20of%2050%25%20skill%20and%20thus%20depend%20predominantly%20on%20chance.%20In%20fact%2C%20poker%20contains%20about%20as%20much%20skill%20as%20chess%20when%203%20out%20of%204%20chess%20games%20are%20replaced%20by%20a%20coin%20%5Cufb02ip.%22%2C%22date%22%3A%2208%5C%2F2020%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1016%5C%2Fj.euroecorev.2020.103472%22%2C%22ISSN%22%3A%2200142921%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Flinkinghub.elsevier.com%5C%2Fretrieve%5C%2Fpii%5C%2FS0014292120301045%22%2C%22collections%22%3A%5B%22IFJ5FWUK%22%5D%2C%22dateModified%22%3A%222020-07-05T07%3A41%3A26Z%22%7D%7D%2C%7B%22key%22%3A%22U5SMXHH9%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Lee%20and%20Courey%22%2C%22parsedDate%22%3A%222020-06-26%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BLee%2C%20M.%20D.%2C%20%26amp%3B%20Courey%2C%20K.%20A.%20%282020%29.%20Modeling%20Optimal%20Stopping%20in%20Changing%20Environments%3A%20a%20Case%20Study%20in%20Mate%20Selection.%20%26lt%3Bi%26gt%3BComputational%20Brain%20%26amp%3B%20Behavior%26lt%3B%5C%2Fi%26gt%3B.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-020-00085-9%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-020-00085-9%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Modeling%20Optimal%20Stopping%20in%20Changing%20Environments%3A%20a%20Case%20Study%20in%20Mate%20Selection%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Michael%20D.%22%2C%22lastName%22%3A%22Lee%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Karyssa%20A.%22%2C%22lastName%22%3A%22Courey%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222020-6-26%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1007%5C%2Fs42113-020-00085-9%22%2C%22ISSN%22%3A%222522-0861%2C%202522-087X%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Flink.springer.com%5C%2F10.1007%5C%2Fs42113-020-00085-9%22%2C%22collections%22%3A%5B%22IFJ5FWUK%22%5D%2C%22dateModified%22%3A%222020-07-02T10%3A00%3A48Z%22%7D%7D%2C%7B%22key%22%3A%22ATEI2KWZ%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Xie%20et%20al.%22%2C%22parsedDate%22%3A%222020-06-29%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BXie%2C%20W.%2C%20Bainbridge%2C%20W.%20A.%2C%20Inati%2C%20S.%20K.%2C%20Baker%2C%20C.%20I.%2C%20%26amp%3B%20Zaghloul%2C%20K.%20A.%20%282020%29.%20Memorability%20of%20words%20in%20arbitrary%20verbal%20associations%20modulates%20memory%20retrieval%20in%20the%20anterior%20temporal%20lobe.%20%26lt%3Bi%26gt%3BNature%20Human%20Behaviour%26lt%3B%5C%2Fi%26gt%3B.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1038%5C%2Fs41562-020-0901-2%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1038%5C%2Fs41562-020-0901-2%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Memorability%20of%20words%20in%20arbitrary%20verbal%20associations%20modulates%20memory%20retrieval%20in%20the%20anterior%20temporal%20lobe%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Weizhen%22%2C%22lastName%22%3A%22Xie%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Wilma%20A.%22%2C%22lastName%22%3A%22Bainbridge%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Sara%20K.%22%2C%22lastName%22%3A%22Inati%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Chris%20I.%22%2C%22lastName%22%3A%22Baker%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Kareem%20A.%22%2C%22lastName%22%3A%22Zaghloul%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222020-6-29%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1038%5C%2Fs41562-020-0901-2%22%2C%22ISSN%22%3A%222397-3374%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.nature.com%5C%2Farticles%5C%2Fs41562-020-0901-2%22%2C%22collections%22%3A%5B%224PWQDPMP%22%5D%2C%22dateModified%22%3A%222020-06-29T16%3A55%3A06Z%22%7D%7D%2C%7B%22key%22%3A%22HB6CRMQD%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Frigg%20and%20Hartmann%22%2C%22parsedDate%22%3A%222006-02-27%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BFrigg%2C%20R.%2C%20%26amp%3B%20Hartmann%2C%20S.%20%282006%29.%20Models%20in%20Science.%20Retrieved%20from%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fstanford.library.sydney.edu.au%5C%2Farchives%5C%2Ffall2012%5C%2Fentries%5C%2Fmodels-science%5C%2F%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fstanford.library.sydney.edu.au%5C%2Farchives%5C%2Ffall2012%5C%2Fentries%5C%2Fmodels-science%5C%2F%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Models%20in%20Science%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Roman%22%2C%22lastName%22%3A%22Frigg%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Stephan%22%2C%22lastName%22%3A%22Hartmann%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222006%5C%2F02%5C%2F27%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fstanford.library.sydney.edu.au%5C%2Farchives%5C%2Ffall2012%5C%2Fentries%5C%2Fmodels-science%5C%2F%22%2C%22collections%22%3A%5B%22ZD5U26MV%22%5D%2C%22dateModified%22%3A%222020-06-26T09%3A21%3A31Z%22%7D%7D%2C%7B%22key%22%3A%22AAY65WYG%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Greenland%20et%20al.%22%2C%22parsedDate%22%3A%222020%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BGreenland%2C%20S.%2C%20Madure%2C%20M.%2C%20Schlesselman%2C%20J.%20J.%2C%20Poole%2C%20C.%2C%20%26amp%3B%20Morgenstern%2C%20H.%20%282020%29.%20Standardized%20Regression%20Coefficients%3A%20A%20Further%20Critique%20and%20Review%20of%20Some%20Alternatives%2C%207.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Standardized%20Regression%20Coefficients%3A%20A%20Further%20Critique%20and%20Review%20of%20Some%20Alternatives%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Sander%22%2C%22lastName%22%3A%22Greenland%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Malcolm%22%2C%22lastName%22%3A%22Madure%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22James%20J%22%2C%22lastName%22%3A%22Schlesselman%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Charles%22%2C%22lastName%22%3A%22Poole%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Hal%22%2C%22lastName%22%3A%22Morgenstern%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222020%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22TIIGTD6N%22%5D%2C%22dateModified%22%3A%222020-06-25T20%3A57%3A55Z%22%7D%7D%2C%7B%22key%22%3A%22D8X56UMN%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Gelman%22%2C%22parsedDate%22%3A%222020-06-22%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BGelman%2C%20A.%20%282020%2C%20June%2022%29.%20Retraction%20of%20racial%20essentialist%20article%20that%20appeared%20in%20Psychological%20Science%20%26%23xAB%3B%26%23x202F%3BStatistical%20Modeling%2C%20Causal%20Inference%2C%20and%20Social%20Science.%20Retrieved%20June%2024%2C%202020%2C%20from%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fstatmodeling.stat.columbia.edu%5C%2F2020%5C%2F06%5C%2F22%5C%2Fretraction-of-racial-essentialist-article-that-appeared-in-psychological-science%5C%2F%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fstatmodeling.stat.columbia.edu%5C%2F2020%5C%2F06%5C%2F22%5C%2Fretraction-of-racial-essentialist-article-that-appeared-in-psychological-science%5C%2F%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22blogPost%22%2C%22title%22%3A%22Retraction%20of%20racial%20essentialist%20article%20that%20appeared%20in%20Psychological%20Science%20%5Cu00ab%20Statistical%20Modeling%2C%20Causal%20Inference%2C%20and%20Social%20Science%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Andrew%22%2C%22lastName%22%3A%22Gelman%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22blogTitle%22%3A%22Statistical%20Modeling%2C%20Causal%20Inference%2C%20and%20Social%20Science%22%2C%22date%22%3A%222020-06-22%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fstatmodeling.stat.columbia.edu%5C%2F2020%5C%2F06%5C%2F22%5C%2Fretraction-of-racial-essentialist-article-that-appeared-in-psychological-science%5C%2F%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%22P5VSV2GV%22%5D%2C%22dateModified%22%3A%222020-06-24T17%3A45%3A37Z%22%7D%7D%2C%7B%22key%22%3A%22354RK8ZQ%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Rozeboom%22%2C%22parsedDate%22%3A%221970-12-31%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BRozeboom%2C%20W.%20W.%20%281970%29.%202.%20The%20Art%20of%20Metascience%2C%20or%2C%20What%20Should%20a%20Psychological%20Theory%20Be%3F%20In%20J.%20Royce%20%28Ed.%29%2C%20%26lt%3Bi%26gt%3BToward%20Unification%20in%20Psychology%26lt%3B%5C%2Fi%26gt%3B%20%28pp.%2053%26%23x2013%3B164%29.%20Toronto%3A%20University%20of%20Toronto%20Press.%20https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3138%5C%2F9781487577506-003%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22bookSection%22%2C%22title%22%3A%222.%20The%20Art%20of%20Metascience%2C%20or%2C%20What%20Should%20a%20Psychological%20Theory%20Be%3F%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22editor%22%2C%22firstName%22%3A%22Joseph%22%2C%22lastName%22%3A%22Royce%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22William%20W.%22%2C%22lastName%22%3A%22Rozeboom%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22bookTitle%22%3A%22Toward%20Unification%20in%20Psychology%22%2C%22date%22%3A%221970-12-31%22%2C%22language%22%3A%22en%22%2C%22ISBN%22%3A%22978-1-4875-7750-6%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.degruyter.com%5C%2Fview%5C%2Fbooks%5C%2F9781487577506%5C%2F9781487577506-003%5C%2F9781487577506-003.xml%22%2C%22collections%22%3A%5B%22T4APK9BM%22%5D%2C%22dateModified%22%3A%222020-06-24T15%3A21%3A19Z%22%7D%7D%2C%7B%22key%22%3A%229HVX9YRX%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Gneiting%20and%20Raftery%22%2C%22parsedDate%22%3A%222007%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BGneiting%2C%20T.%2C%20%26amp%3B%20Raftery%2C%20A.%20E.%20%282007%29.%20Strictly%20Proper%20Scoring%20Rules%2C%20Prediction%2C%20and%20Estimation.%20%26lt%3Bi%26gt%3BJournal%20of%20the%20American%20Statistical%20Association%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B102%26lt%3B%5C%2Fi%26gt%3B%28477%29%2C%20359%26%23x2013%3B378.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1198%5C%2F016214506000001437%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1198%5C%2F016214506000001437%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Strictly%20Proper%20Scoring%20Rules%2C%20Prediction%2C%20and%20Estimation%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Tilmann%22%2C%22lastName%22%3A%22Gneiting%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adrian%20E%22%2C%22lastName%22%3A%22Raftery%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%2203%5C%2F2007%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1198%5C%2F016214506000001437%22%2C%22ISSN%22%3A%220162-1459%2C%201537-274X%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.tandfonline.com%5C%2Fdoi%5C%2Fabs%5C%2F10.1198%5C%2F016214506000001437%22%2C%22collections%22%3A%5B%22T4APK9BM%22%5D%2C%22dateModified%22%3A%222020-06-24T13%3A56%3A02Z%22%7D%7D%2C%7B%22key%22%3A%22CPN9FEZ5%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Rouhani%20et%20al.%22%2C%22parsedDate%22%3A%222020%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BRouhani%2C%20N.%2C%20Norman%2C%20K.%20A.%2C%20Niv%2C%20Y.%2C%20%26amp%3B%20Bornstein%2C%20A.%20M.%20%282020%29.%20Reward%20prediction%20errors%20create%20event%20boundaries%20in%20memory.%20%26lt%3Bi%26gt%3BCognition%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B203%26lt%3B%5C%2Fi%26gt%3B%2C%20104269.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.cognition.2020.104269%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.cognition.2020.104269%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Reward%20prediction%20errors%20create%20event%20boundaries%20in%20memory%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Nina%22%2C%22lastName%22%3A%22Rouhani%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Kenneth%20A.%22%2C%22lastName%22%3A%22Norman%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Yael%22%2C%22lastName%22%3A%22Niv%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Aaron%20M.%22%2C%22lastName%22%3A%22Bornstein%22%7D%5D%2C%22abstractNote%22%3A%22We%20remember%20when%20things%20change.%20Particularly%20salient%20are%20experiences%20where%20there%20is%20a%20change%20in%20rewards%2C%20eliciting%20reward%20prediction%20errors%20%28RPEs%29.%20How%20do%20RPEs%20in%5Cufb02uence%20our%20memory%20of%20those%20experiences%3F%20One%20idea%20is%20that%20this%20signal%20directly%20enhances%20the%20encoding%20of%20memory.%20Another%2C%20not%20mutually%20exclusive%2C%20idea%20is%20that%20the%20RPE%20signals%20a%20deeper%20change%20in%20the%20environment%2C%20leading%20to%20the%20mnemonic%20separation%20of%20subsequent%20experiences%20from%20what%20came%20before%2C%20thereby%20creating%20a%20new%20latent%20context%20and%20a%20more%20separate%20memory%20trace.%20We%20tested%20this%20in%20four%20experiments%20where%20participants%20learned%20to%20predict%20rewards%20associated%20with%20a%20series%20of%20trial-unique%20images.%20High-magnitude%20RPEs%20indicated%20a%20change%20in%20the%20underlying%20distribution%20of%20rewards.%20To%20test%20whether%20these%20large%20RPEs%20created%20a%20new%20latent%20context%2C%20we%20%5Cufb01rst%20assessed%20recognition%20priming%20for%20sequential%20pairs%20that%20included%20a%20highRPE%20event%20or%20not%20%28Exp.%201%3A%20n%20%3D%2027%20%26amp%3B%20Exp.%202%3A%20n%20%3D%2083%29.%20We%20found%20evidence%20of%20recognition%20priming%20for%20the%20high-RPE%20event%2C%20indicating%20that%20the%20high-RPE%20event%20is%20bound%20to%20its%20predecessor%20in%20memory.%20Given%20that%20high-RPE%20events%20are%20themselves%20preferentially%20remembered%20%28Rouhani%2C%20Norman%2C%20%26amp%3B%20Niv%2C%202018%29%2C%20we%20next%20tested%20whether%20there%20was%20an%20event%20boundary%20across%20a%20high-RPE%20event%20%28i.e.%2C%20excluding%20the%20high-RPE%20event%20itself%3B%20Exp.%203%3A%20n%20%3D%2085%29.%20Here%2C%20sequential%20pairs%20across%20a%20high%20RPE%20no%20longer%20showed%20recognition%20priming%20whereas%20pairs%20within%20the%20same%20latent%20reward%20state%20did%2C%20providing%20initial%20evidence%20for%20an%20RPE-modulated%20event%20boundary.%20We%20then%20investigated%20whether%20RPE%20event%20boundaries%20disrupt%20temporal%20memory%20by%20asking%20participants%20to%20order%20and%20estimate%20the%20distance%20between%20two%20events%20that%20had%20either%20included%20a%20high-RPE%20event%20between%20them%20or%20not%20%28Exp.%204%29.%20We%20found%20%28n%20%3D%2049%29%20and%20replicated%20%28n%20%3D%2077%29%20worse%20sequence%20memory%20for%20events%20across%20a%20high%20RPE.%20In%20line%20with%20our%20recognition%20priming%20results%2C%20we%20did%20not%20%5Cufb01nd%20sequence%20memory%20to%20be%20impaired%20between%20the%20high-RPE%20event%20and%20its%20predecessor%2C%20but%20instead%20found%20worse%20sequence%20memory%20for%20pairs%20across%20a%20high-RPE%20event.%20Moreover%2C%20greater%20distance%20between%20events%20at%20encoding%20led%20to%20better%20sequence%20memory%20for%20events%20across%20a%20low-RPE%20event%2C%20but%20not%20a%20high-RPE%20event%2C%20suggesting%20separate%20mechanisms%20for%20the%20temporal%20ordering%20of%20events%20within%20versus%20across%20a%20latent%20reward%20context.%20Altogether%2C%20these%20%5Cufb01ndings%20demonstrate%20that%20high-RPE%20events%20are%20both%20more%20strongly%20encoded%2C%20show%20intact%20links%20with%20their%20predecessor%2C%20and%20act%20as%20event%20boundaries%20that%20interrupt%20the%20sequential%20integration%20of%20events.%20We%20captured%20these%20e%5Cufb00ects%20in%20a%20variant%20of%20the%20Context%20Maintenance%20and%20Retrieval%20model%20%28CMR%3B%20Polyn%2C%20Norman%2C%20%26amp%3B%20Kahana%2C%202009%29%2C%20modi%5Cufb01ed%20to%20incorporate%20RPEs%20into%20the%20encoding%20process.%22%2C%22date%22%3A%2210%5C%2F2020%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1016%5C%2Fj.cognition.2020.104269%22%2C%22ISSN%22%3A%2200100277%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Flinkinghub.elsevier.com%5C%2Fretrieve%5C%2Fpii%5C%2FS0010027720300883%22%2C%22collections%22%3A%5B%224PWQDPMP%22%5D%2C%22dateModified%22%3A%222020-06-22T20%3A34%3A00Z%22%7D%7D%2C%7B%22key%22%3A%222YD6ER9F%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Robinson%20et%20al.%22%2C%22parsedDate%22%3A%222020%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BRobinson%2C%20M.%20M.%2C%20Benjamin%2C%20A.%20S.%2C%20%26amp%3B%20Irwin%2C%20D.%20E.%20%282020%29.%20Is%20there%20a%20K%20in%20capacity%3F%20Assessing%20the%20structure%20of%20visual%20short-term%20memory.%20%26lt%3Bi%26gt%3BCognitive%20Psychology%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B121%26lt%3B%5C%2Fi%26gt%3B%2C%20101305.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.cogpsych.2020.101305%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.cogpsych.2020.101305%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Is%20there%20a%20K%20in%20capacity%3F%20Assessing%20the%20structure%20of%20visual%20short-term%20memory%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Maria%20M.%22%2C%22lastName%22%3A%22Robinson%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Aaron%20S.%22%2C%22lastName%22%3A%22Benjamin%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22David%20E.%22%2C%22lastName%22%3A%22Irwin%22%7D%5D%2C%22abstractNote%22%3A%22Visual%20short-term%20memory%20%28VSTM%29%20is%20a%20cognitive%20structure%20that%20temporarily%20maintains%20a%20limited%20amount%20of%20visual%20information%20in%20the%20service%20of%20current%20cognitive%20goals.%20There%20is%20active%20theoretical%20debate%20regarding%20how%20limits%20in%20VSTM%20should%20be%20construed.%20According%20to%20discrete-slot%20models%20of%20capacity%2C%20these%20limits%20are%20set%20in%20terms%20of%20a%20discrete%20number%20of%20slots%20that%20store%20individual%20objects%20in%20an%20all-or-none%20fashion.%20According%20to%20alternative%20continuous%20resource%20models%2C%20the%20limits%20of%20VSTM%20are%20set%20in%20terms%20of%20a%20resource%20that%20can%20be%20distributed%20to%20bolster%20some%20representations%20over%20others%20in%20a%20graded%20fashion.%20Hybrid%20models%20have%20also%20been%20proposed.%20We%20tackled%20the%20classic%20question%20of%20how%20to%20construe%20VSTM%20structure%20in%20a%20novel%20way%2C%20by%20examining%20how%20contending%20models%20explain%20data%20within%20traditional%20VSTM%20tasks%20and%20also%20how%20they%20generalize%20across%20different%20VSTM%20tasks.%20Specifically%2C%20we%20fit%20theoretical%20ROCs%20derived%20from%20a%20suite%20of%20models%20to%20two%20popular%20VSTM%20tasks%3A%20a%20change%20detection%20task%20in%20which%20participants%20had%20to%20remember%20simple%20features%20and%20a%20rapid%20serial%20visual%20presentation%20task%20in%20which%20participants%20had%20to%20remember%20real-world%20objects.%20In%203%20experiments%20we%20assessed%20the%20fit%20and%20predictive%20ability%20of%20each%20model%20and%20found%20consistent%20support%20for%20pure%20resource%20models%20of%20VSTM.%20To%20gain%20a%20fuller%20understanding%20of%20the%20nature%20of%20limits%20in%20VSTM%2C%20we%20also%20evaluated%20the%20ability%20of%20these%20models%20to%20jointly%20model%20the%20two%20tasks.%20These%20joint%20modeling%20analyses%20revealed%20additional%20support%20for%20pure%20continuous-resource%20models%2C%20but%20also%20evidence%20that%20performance%20across%20the%20two%20tasks%20cannot%20be%20captured%20by%20a%20common%20set%20of%20parameters.%20We%20provide%20an%20interpretation%20of%20these%20signal%20detection%20models%20that%20align%20with%20the%20idea%20that%20differences%20among%20memoranda%20and%20across%20encoding%20conditions%20alter%20the%20memory%20signal%20of%20representations%20in%20VSTM.%22%2C%22date%22%3A%2209%5C%2F2020%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1016%5C%2Fj.cogpsych.2020.101305%22%2C%22ISSN%22%3A%2200100285%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Flinkinghub.elsevier.com%5C%2Fretrieve%5C%2Fpii%5C%2FS0010028520300347%22%2C%22collections%22%3A%5B%226X876M3T%22%5D%2C%22dateModified%22%3A%222020-06-22T10%3A59%3A10Z%22%7D%7D%2C%7B%22key%22%3A%22DY7XUFCB%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Lee%20et%20al.%22%2C%22parsedDate%22%3A%222019-12-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BLee%2C%20M.%20D.%2C%20Criss%2C%20A.%20H.%2C%20Devezer%2C%20B.%2C%20Donkin%2C%20C.%2C%20Etz%2C%20A.%2C%20Leite%2C%20F.%20P.%2C%20%26%23x2026%3B%20Vandekerckhove%2C%20J.%20%282019%29.%20Robust%20Modeling%20in%20Cognitive%20Science.%20%26lt%3Bi%26gt%3BComputational%20Brain%20%26amp%3B%20Behavior%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B2%26lt%3B%5C%2Fi%26gt%3B%283%29%2C%20141%26%23x2013%3B153.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-019-00029-y%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-019-00029-y%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Robust%20Modeling%20in%20Cognitive%20Science%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Michael%20D.%22%2C%22lastName%22%3A%22Lee%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Amy%20H.%22%2C%22lastName%22%3A%22Criss%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Berna%22%2C%22lastName%22%3A%22Devezer%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Christopher%22%2C%22lastName%22%3A%22Donkin%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Alexander%22%2C%22lastName%22%3A%22Etz%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22F%5Cu00e1bio%20P.%22%2C%22lastName%22%3A%22Leite%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Dora%22%2C%22lastName%22%3A%22Matzke%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Jeffrey%20N.%22%2C%22lastName%22%3A%22Rouder%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Jennifer%20S.%22%2C%22lastName%22%3A%22Trueblood%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Corey%20N.%22%2C%22lastName%22%3A%22White%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Joachim%22%2C%22lastName%22%3A%22Vandekerckhove%22%7D%5D%2C%22abstractNote%22%3A%22In%20an%20attempt%20to%20increase%20the%20reliability%20of%20empirical%20findings%2C%20psychological%20scientists%20have%20recently%20proposed%20a%20number%20of%20changes%20in%20the%20practice%20of%20experimental%20psychology.%20Most%20current%20reform%20efforts%20have%20focused%20on%20the%20analysis%20of%20data%20and%20the%20reporting%20of%20findings%20for%20empirical%20studies.%20However%2C%20a%20large%20contingent%20of%20psychologists%20build%20models%20that%20explain%20psychological%20processes%20and%20test%20psychological%20theories%20using%20formal%20psychological%20models.%20Some%2C%20but%20not%20all%2C%20recommendations%20borne%20out%20of%20the%20broader%20reform%20movement%20bear%20upon%20the%20practice%20of%20behavioral%20or%20cognitive%20modeling.%20In%20this%20article%2C%20we%20consider%20which%20aspects%20of%20the%20current%20reform%20movement%20are%20relevant%20to%20psychological%20modelers%2C%20and%20we%20propose%20a%20number%20of%20techniques%20and%20practices%20aimed%20at%20making%20psychological%20modeling%20more%20transparent%2C%20trusted%2C%20and%20robust.%22%2C%22date%22%3A%222019-12-01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1007%5C%2Fs42113-019-00029-y%22%2C%22ISSN%22%3A%222522-087X%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-019-00029-y%22%2C%22collections%22%3A%5B%22T4APK9BM%22%5D%2C%22dateModified%22%3A%222020-06-18T19%3A27%3A13Z%22%7D%7D%2C%7B%22key%22%3A%22XTHZTV8G%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Bailer-Jones%22%2C%22parsedDate%22%3A%222009%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BBailer-Jones%2C%20D.%20%282009%29.%20%26lt%3Bi%26gt%3BScientific%20models%20in%20philosophy%20of%20science%26lt%3B%5C%2Fi%26gt%3B.%20Pittsburgh%2C%20Pa.%2C%3A%20University%20of%20Pittsburgh%20Press.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22book%22%2C%22title%22%3A%22Scientific%20models%20in%20philosophy%20of%20science%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Daniela%22%2C%22lastName%22%3A%22Bailer-Jones%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222009%22%2C%22language%22%3A%22English%22%2C%22ISBN%22%3A%22978-0-8229-6273-1%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22T4APK9BM%22%5D%2C%22dateModified%22%3A%222020-06-18T19%3A02%3A26Z%22%7D%7D%2C%7B%22key%22%3A%22UXXLJJ5E%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Suppes%22%2C%22parsedDate%22%3A%222002%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BSuppes%2C%20P.%20%282002%29.%20%26lt%3Bi%26gt%3BRepresentation%20and%20invariance%20of%20scientific%20structures%26lt%3B%5C%2Fi%26gt%3B.%20Stanford%2C%20Calif.%3A%20CSLI%20Publications.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22book%22%2C%22title%22%3A%22Representation%20and%20invariance%20of%20scientific%20structures%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Patrick%22%2C%22lastName%22%3A%22Suppes%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222002%22%2C%22language%22%3A%22English%22%2C%22ISBN%22%3A%22978-1-57586-333-7%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22T4APK9BM%22%5D%2C%22dateModified%22%3A%222020-06-18T19%3A00%3A31Z%22%7D%7D%2C%7B%22key%22%3A%22MJGW4VGX%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Roy%22%2C%22parsedDate%22%3A%222003-01-09%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BRoy%2C%20D.%20%282003%29.%20The%20Discrete%20Normal%20Distribution.%20%26lt%3Bi%26gt%3BCommunications%20in%20Statistics%20-%20Theory%20and%20Methods%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B32%26lt%3B%5C%2Fi%26gt%3B%2810%29%2C%201871%26%23x2013%3B1883.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1081%5C%2FSTA-120023256%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1081%5C%2FSTA-120023256%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22The%20Discrete%20Normal%20Distribution%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Dilip%22%2C%22lastName%22%3A%22Roy%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222003-01-09%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1081%5C%2FSTA-120023256%22%2C%22ISSN%22%3A%220361-0926%2C%201532-415X%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.tandfonline.com%5C%2Fdoi%5C%2Fabs%5C%2F10.1081%5C%2FSTA-120023256%22%2C%22collections%22%3A%5B%22T4APK9BM%22%5D%2C%22dateModified%22%3A%222020-06-17T11%3A28%3A49Z%22%7D%7D%2C%7B%22key%22%3A%229LIFURNV%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Ospina%20and%20Ferrari%22%2C%22parsedDate%22%3A%222012-06-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BOspina%2C%20R.%2C%20%26amp%3B%20Ferrari%2C%20S.%20L.%20P.%20%282012%29.%20A%20general%20class%20of%20zero-or-one%20inflated%20beta%20regression%20models.%20%26lt%3Bi%26gt%3BComputational%20Statistics%20%26amp%3B%20Data%20Analysis%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B56%26lt%3B%5C%2Fi%26gt%3B%286%29%2C%201609%26%23x2013%3B1623.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.csda.2011.10.005%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.csda.2011.10.005%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22A%20general%20class%20of%20zero-or-one%20inflated%20beta%20regression%20models%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Raydonal%22%2C%22lastName%22%3A%22Ospina%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Silvia%20L.%20P.%22%2C%22lastName%22%3A%22Ferrari%22%7D%5D%2C%22abstractNote%22%3A%22This%20paper%20proposes%20a%20general%20class%20of%20regression%20models%20for%20continuous%20proportions%20when%20the%20data%20contain%20zeros%20or%20ones.%20The%20proposed%20class%20of%20models%20assumes%20that%20the%20response%20variable%20has%20a%20mixed%20continuous%5Cu2013discrete%20distribution%20with%20probability%20mass%20at%20zero%20or%20one.%20The%20beta%20distribution%20is%20used%20to%20describe%20the%20continuous%20component%20of%20the%20model%2C%20since%20its%20density%20has%20a%20wide%20range%20of%20different%20shapes%20depending%20on%20the%20values%20of%20the%20two%20parameters%20that%20index%20the%20distribution.%20We%20use%20a%20suitable%20parameterization%20of%20the%20beta%20law%20in%20terms%20of%20its%20mean%20and%20a%20precision%20parameter.%20The%20parameters%20of%20the%20mixture%20distribution%20are%20modeled%20as%20functions%20of%20regression%20parameters.%20We%20provide%20inference%2C%20diagnostic%2C%20and%20model%20selection%20tools%20for%20this%20class%20of%20models.%20A%20practical%20application%20that%20employs%20real%20data%20is%20presented.%22%2C%22date%22%3A%22June%201%2C%202012%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1016%5C%2Fj.csda.2011.10.005%22%2C%22ISSN%22%3A%220167-9473%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.sciencedirect.com%5C%2Fscience%5C%2Farticle%5C%2Fpii%5C%2FS0167947311003628%22%2C%22collections%22%3A%5B%22H43IPV6Q%22%5D%2C%22dateModified%22%3A%222020-06-16T17%3A33%3A02Z%22%7D%7D%2C%7B%22key%22%3A%22GG5JY6Y3%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Uygun%20Tun%5Cu00e7%20and%20Tun%5Cu00e7%22%2C%22parsedDate%22%3A%222020-05-13%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BUygun%20Tun%26%23xE7%3B%2C%20D.%2C%20%26amp%3B%20Tun%26%23xE7%3B%2C%20M.%20N.%20%282020%29.%20%26lt%3Bi%26gt%3BA%20Falsificationist%20Treatment%20of%20Auxiliary%20Hypotheses%20in%20Social%20and%20Behavioral%20Sciences%3A%20Systematic%20Replications%20Framework%26lt%3B%5C%2Fi%26gt%3B%20%28preprint%29.%20PsyArXiv.%20https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.31234%5C%2Fosf.io%5C%2Fpdm7y%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22report%22%2C%22title%22%3A%22A%20Falsificationist%20Treatment%20of%20Auxiliary%20Hypotheses%20in%20Social%20and%20Behavioral%20Sciences%3A%20Systematic%20Replications%20Framework%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Duygu%22%2C%22lastName%22%3A%22Uygun%20Tun%5Cu00e7%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Mehmet%20Necip%22%2C%22lastName%22%3A%22Tun%5Cu00e7%22%7D%5D%2C%22abstractNote%22%3A%22Single%20empirical%20tests%20are%20always%20ambiguous%20in%20their%20implications%20for%20the%20theory%20under%20investigation%2C%20because%20non-corroborative%20evidence%20leaves%20us%20underdetermined%20in%20our%20decision%20as%20to%20whether%20the%20main%20hypothesis%20or%20one%20or%20more%20auxiliary%20hypotheses%20should%20bear%20the%20burden%20of%20falsification.%20Methodological%20falsificationism%20tries%20to%20solve%20this%20problem%20by%20relegating%20auxiliary%20hypotheses%20that%20increase%20the%20testability%20of%20theories%20to%20unproblematic%20background%20knowledge%20and%20disallowing%20others.%20However%2C%20decisions%20to%20accept%20such%20auxiliaries%20as%20unproblematic%20are%20seldom%20conclusively%20justified%20in%20the%20social%20and%20behavioral%20sciences%2C%20where%20operationalizations%20play%20a%20central%20role%2C%20but%20are%20much%20less%20theory-driven%20and%20independently%20testable.%20Close%20and%20conceptual%20replications%20are%20crucial%20in%20tackling%20different%20aspects%20of%20underdetermination%2C%20but%20they%20fail%20to%20serve%20this%20purpose%20when%20conducted%20in%20isolation.%20To%20facilitate%20rational%20decision-making%20regarding%20falsifications%2C%20we%20propose%20Systematic%20Replications%20Framework%20%28SRF%29%20that%20organizes%20subsequent%20tests%20into%20a%20pre-planned%20series%20of%20logically%20interlinked%20close%20and%20conceptual%20replications.%20SRF%20reduces%20underdetermination%20by%20disentangling%20the%20implications%20of%20non-corroborative%20findings%20for%20the%20main%20hypothesis%20and%20the%20operationalization-related%20auxiliaries.%20It%20also%20serves%20as%20a%20severe-testing%20procedure%20through%20systematically%20organized%20self-replications.%20SRF%20will%20be%20particularly%20useful%20if%20applied%20to%20contested%20theoretical%20claims%20with%20mixed%20evidence%20and%20realized%20through%20adversarial%20collaboration.%20We%20also%20discuss%20how%20applying%20this%20framework%20can%20scaffold%20judgments%20regarding%20the%20permissibility%20of%20ad%20hoc%20hypothesizing%20in%20reference%20to%20the%20Lakatosian%20notions%20of%20progressive%20and%20degenerative%20research%20programs.%22%2C%22reportNumber%22%3A%22%22%2C%22reportType%22%3A%22preprint%22%2C%22institution%22%3A%22PsyArXiv%22%2C%22date%22%3A%222020-05-13%22%2C%22language%22%3A%22%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fosf.io%5C%2Fpdm7y%22%2C%22collections%22%3A%5B%22P5VSV2GV%22%5D%2C%22dateModified%22%3A%222020-06-16T06%3A51%3A55Z%22%7D%7D%2C%7B%22key%22%3A%22H7L49ZLM%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Murayama%20et%20al.%22%2C%22parsedDate%22%3A%222016%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BMurayama%2C%20K.%2C%20Blake%2C%20A.%20B.%2C%20Kerr%2C%20T.%2C%20%26amp%3B%20Castel%2C%20A.%20D.%20%282016%29.%20When%20enough%20is%20not%20enough%3A%20Information%20overload%20and%20metacognitive%20decisions%20to%20stop%20studying%20information.%20%26lt%3Bi%26gt%3BJournal%20of%20Experimental%20Psychology%3A%20Learning%2C%20Memory%2C%20and%20Cognition%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B42%26lt%3B%5C%2Fi%26gt%3B%286%29%2C%20914%26%23x2013%3B924.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Fxlm0000213%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Fxlm0000213%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22When%20enough%20is%20not%20enough%3A%20Information%20overload%20and%20metacognitive%20decisions%20to%20stop%20studying%20information.%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Kou%22%2C%22lastName%22%3A%22Murayama%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adam%20B.%22%2C%22lastName%22%3A%22Blake%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Tyson%22%2C%22lastName%22%3A%22Kerr%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Alan%20D.%22%2C%22lastName%22%3A%22Castel%22%7D%5D%2C%22abstractNote%22%3A%22People%20are%20often%20exposed%20to%20more%20information%20than%20they%20can%20actually%20remember.%20Despite%20this%20frequent%20form%20of%20information%20overload%2C%20little%20is%20known%20about%20how%20much%20information%20people%20choose%20to%20remember.%20Using%20a%20novel%20%5Cu201cstop%5Cu201d%20paradigm%2C%20the%20current%20research%20examined%20whether%20and%20how%20people%20choose%20to%20stop%20receiving%20new%5Cu2014possibly%20overwhelming%5Cu2014information%20with%20the%20intent%20to%20maximize%20memory%20performance.%20Participants%20were%20presented%20with%20a%20long%20list%20of%20items%20and%20were%20rewarded%20for%20the%20number%20of%20correctly%20remembered%20words%20in%20a%20following%20free%20recall%20test.%20Critically%2C%20participants%20in%20a%20stop%20condition%20were%20provided%20with%20the%20option%20to%20stop%20the%20presentation%20of%20the%20remaining%20words%20at%20any%20time%20during%20the%20list%2C%20whereas%20participants%20in%20a%20control%20condition%20were%20presented%20with%20all%20items.%20Across%205%20experiments%2C%20the%20authors%20found%20that%20participants%20tended%20to%20stop%20the%20presentation%20of%20the%20items%20to%20maximize%20the%20number%20of%20recalled%20items%2C%20but%20this%20decision%20ironically%20led%20to%20decreased%20memory%20performance%20relative%20to%20the%20control%20group.%20This%20pattern%20was%20consistent%20even%20after%20controlling%20for%20possible%20confounding%20factors%20%28e.g.%2C%20task%20demands%29.%20The%20results%20indicated%20a%20general%2C%20false%20belief%20that%20we%20can%20remember%20a%20larger%20number%20of%20items%20if%20we%20restrict%20the%20quantity%20of%20learning%20materials.%20These%20findings%20suggest%20people%20have%20an%20incomplete%20understanding%20of%20how%20we%20remember%20excessive%20amounts%20of%20information.%22%2C%22date%22%3A%2206%5C%2F2016%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1037%5C%2Fxlm0000213%22%2C%22ISSN%22%3A%221939-1285%2C%200278-7393%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fdoi.apa.org%5C%2Fgetdoi.cfm%3Fdoi%3D10.1037%5C%2Fxlm0000213%22%2C%22collections%22%3A%5B%224PWQDPMP%22%5D%2C%22dateModified%22%3A%222020-06-10T19%3A29%3A31Z%22%7D%7D%2C%7B%22key%22%3A%22T8QYE4LP%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Jefferys%20and%20Berger%22%2C%22parsedDate%22%3A%221992%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BJefferys%2C%20W.%20H.%2C%20%26amp%3B%20Berger%2C%20J.%20O.%20%281992%29.%20Ockham%26%23x2019%3Bs%20Razor%20and%20Bayesian%20Analysis.%20%26lt%3Bi%26gt%3BAmerican%20Scientist%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B80%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%2064%26%23x2013%3B72.%20Retrieved%20from%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fwww.jstor.org%5C%2Fstable%5C%2F29774559%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fwww.jstor.org%5C%2Fstable%5C%2F29774559%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Ockham%27s%20Razor%20and%20Bayesian%20Analysis%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22William%20H.%22%2C%22lastName%22%3A%22Jefferys%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22James%20O.%22%2C%22lastName%22%3A%22Berger%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%221992%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22ISSN%22%3A%220003-0996%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fwww.jstor.org%5C%2Fstable%5C%2F29774559%22%2C%22collections%22%3A%5B%2232HV3NV5%22%5D%2C%22dateModified%22%3A%222020-06-07T15%3A04%3A01Z%22%7D%7D%2C%7B%22key%22%3A%22LQBGD2BB%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Maier%20et%20al.%22%2C%22parsedDate%22%3A%222020-06-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BMaier%2C%20S.%20U.%2C%20Raja%20Beharelle%2C%20A.%2C%20Polan%26%23xED%3Ba%2C%20R.%2C%20Ruff%2C%20C.%20C.%2C%20%26amp%3B%20Hare%2C%20T.%20A.%20%282020%29.%20Dissociable%20mechanisms%20govern%20when%20and%20how%20strongly%20reward%20attributes%20affect%20decisions.%20%26lt%3Bi%26gt%3BNature%20Human%20Behaviour%26lt%3B%5C%2Fi%26gt%3B.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1038%5C%2Fs41562-020-0893-y%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1038%5C%2Fs41562-020-0893-y%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Dissociable%20mechanisms%20govern%20when%20and%20how%20strongly%20reward%20attributes%20affect%20decisions%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Silvia%20U.%22%2C%22lastName%22%3A%22Maier%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Anjali%22%2C%22lastName%22%3A%22Raja%20Beharelle%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Rafael%22%2C%22lastName%22%3A%22Polan%5Cu00eda%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Christian%20C.%22%2C%22lastName%22%3A%22Ruff%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Todd%20A.%22%2C%22lastName%22%3A%22Hare%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222020-6-1%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1038%5C%2Fs41562-020-0893-y%22%2C%22ISSN%22%3A%222397-3374%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.nature.com%5C%2Farticles%5C%2Fs41562-020-0893-y%22%2C%22collections%22%3A%5B%22TT83T9T4%22%5D%2C%22dateModified%22%3A%222020-06-04T13%3A10%3A26Z%22%7D%7D%2C%7B%22key%22%3A%22HQ228ZB7%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Nadarajah%22%2C%22parsedDate%22%3A%222009-01-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BNadarajah%2C%20S.%20%282009%29.%20An%20alternative%20inverse%20Gaussian%20distribution.%20%26lt%3Bi%26gt%3BMathematics%20and%20Computers%20in%20Simulation%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B79%26lt%3B%5C%2Fi%26gt%3B%285%29%2C%201721%26%23x2013%3B1729.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.matcom.2008.08.013%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2Fj.matcom.2008.08.013%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22An%20alternative%20inverse%20Gaussian%20distribution%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Saralees%22%2C%22lastName%22%3A%22Nadarajah%22%7D%5D%2C%22abstractNote%22%3A%22An%20alternative%20inverse%20Gaussian%20distribution%20expressed%20in%20terms%20of%20the%20Bessel%20function%20is%20introduced.%20Both%20theoretical%20and%20empirical%20motivation%20is%20provided.%20Various%20particular%20cases%20and%20expressions%20for%20moments%20are%20derived.%20Estimation%20procedures%20by%20the%20method%20of%20moments%20and%20the%20method%20of%20maximum%20likelihood%20as%20well%20as%20the%20associated%20Fisher%20information%20matrix%20are%20derived.%20A%20simulation%20study%20is%20performed%20to%20investigate%20the%20asymptotic%20distribution%20of%20an%20associated%20boundary%20crossing%20variable.%20Finally%2C%20an%20application%20is%20illustrated%20to%20show%20that%20the%20proposed%20distribution%20can%20be%20a%20better%20model%20for%20reliability%20data%20than%20one%20based%20on%20the%20standard%20inverse%20Gaussian%20distribution.%22%2C%22date%22%3A%22January%201%2C%202009%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1016%5C%2Fj.matcom.2008.08.013%22%2C%22ISSN%22%3A%220378-4754%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.sciencedirect.com%5C%2Fscience%5C%2Farticle%5C%2Fpii%5C%2FS0378475408003066%22%2C%22collections%22%3A%5B%22TT83T9T4%22%5D%2C%22dateModified%22%3A%222020-05-31T09%3A23%3A04Z%22%7D%7D%2C%7B%22key%22%3A%228ESHCJR5%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Barndorff-Nielsen%20et%20al.%22%2C%22parsedDate%22%3A%221978-03-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BBarndorff-Nielsen%2C%20O.%2C%20Bl%26%23xC6%3Bsild%2C%20P.%2C%20%26amp%3B%20Halgreen%2C%20C.%20%281978%29.%20First%20hitting%20time%20models%20for%20the%20generalized%20inverse%20Gaussian%20distribution.%20%26lt%3Bi%26gt%3BStochastic%20Processes%20and%20Their%20Applications%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B7%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%2049%26%23x2013%3B54.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2F0304-4149%2878%2990036-4%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1016%5C%2F0304-4149%2878%2990036-4%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22First%20hitting%20time%20models%20for%20the%20generalized%20inverse%20Gaussian%20distribution%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22O.%22%2C%22lastName%22%3A%22Barndorff-Nielsen%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22P.%22%2C%22lastName%22%3A%22Bl%5Cu00c6sild%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22C.%22%2C%22lastName%22%3A%22Halgreen%22%7D%5D%2C%22abstractNote%22%3A%22Any%20generalized%20inverse%20Gaussian%20distribution%20with%20a%20non-positive%20power%20parameter%20is%20shown%20to%20be%20the%20distribution%20of%20the%20first%20hitting%20time%20of%20level%200%20for%20each%20of%20a%20variety%20of%20time-homogeneous%20diffusions%20on%20the%20interval%20%5B0%2C%20%5Cu221e%29.%20The%20infinite%20divisibility%20of%20the%20generalized%20inverse%20Gaussian%20distributions%20is%20a%20simple%20consequence%20of%20this%20and%20an%20elementary%20convolution%20formula%20for%20these%20distributions.%22%2C%22date%22%3A%22March%201%2C%201978%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1016%5C%2F0304-4149%2878%2990036-4%22%2C%22ISSN%22%3A%220304-4149%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.sciencedirect.com%5C%2Fscience%5C%2Farticle%5C%2Fpii%5C%2F0304414978900364%22%2C%22collections%22%3A%5B%22TT83T9T4%22%5D%2C%22dateModified%22%3A%222020-05-31T09%3A17%3A43Z%22%7D%7D%2C%7B%22key%22%3A%226IJQ955S%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Ghitany%20et%20al.%22%2C%22parsedDate%22%3A%222019-07-18%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BGhitany%2C%20M.%20E.%2C%20Mazucheli%2C%20J.%2C%20Menezes%2C%20A.%20F.%20B.%2C%20%26amp%3B%20Alqallaf%2C%20F.%20%282019%29.%20The%20unit-inverse%20Gaussian%20distribution%3A%20A%20new%20alternative%20to%20two-parameter%20distributions%20on%20the%20unit%20interval.%20%26lt%3Bi%26gt%3BCommunications%20in%20Statistics%20-%20Theory%20and%20Methods%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B48%26lt%3B%5C%2Fi%26gt%3B%2814%29%2C%203423%26%23x2013%3B3438.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F03610926.2018.1476717%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F03610926.2018.1476717%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22The%20unit-inverse%20Gaussian%20distribution%3A%20A%20new%20alternative%20to%20two-parameter%20distributions%20on%20the%20unit%20interval%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22M.%20E.%22%2C%22lastName%22%3A%22Ghitany%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22J.%22%2C%22lastName%22%3A%22Mazucheli%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22A.%20F.%20B.%22%2C%22lastName%22%3A%22Menezes%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22F.%22%2C%22lastName%22%3A%22Alqallaf%22%7D%5D%2C%22abstractNote%22%3A%22A%20new%20two-parameter%20distribution%20over%20the%20unit%20interval%2C%20called%20the%20Unit-Inverse%20Gaussian%20distribution%2C%20is%20introduced%20and%20studied%20in%20detail.%20The%20proposed%20distribution%20shares%20many%20properties%20with%20other%20known%20distributions%20on%20the%20unit%20interval%2C%20such%20as%20Beta%2C%20Johnson%20SB%2C%20Unit-Gamma%2C%20and%20Kumaraswamy%20distributions.%20Estimation%20of%20the%20parameters%20of%20the%20proposed%20distribution%20are%20obtained%20by%20transforming%20the%20data%20to%20the%20inverse%20Gaussian%20distribution.%20Unlike%20most%20distributions%20on%20the%20unit%20interval%2C%20the%20maximum%20likelihood%20or%20method%20of%20moments%20estimators%20of%20the%20parameters%20of%20the%20proposed%20distribution%20are%20expressed%20in%20simple%20closed%20forms%20which%20do%20not%20need%20iterative%20methods%20to%20compute.%20Application%20of%20the%20proposed%20distribution%20to%20a%20real%20data%20set%20shows%20better%20fit%20than%20many%20known%20two-parameter%20distributions%20on%20the%20unit%20interval.%22%2C%22date%22%3A%22July%2018%2C%202019%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%2210.1080%5C%2F03610926.2018.1476717%22%2C%22ISSN%22%3A%220361-0926%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F03610926.2018.1476717%22%2C%22collections%22%3A%5B%22H43IPV6Q%22%5D%2C%22dateModified%22%3A%222020-05-31T08%3A55%3A06Z%22%7D%7D%2C%7B%22key%22%3A%22IJQUKNRK%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Weichart%20et%20al.%22%2C%22parsedDate%22%3A%222020-03-26%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BWeichart%2C%20E.%20R.%2C%20Turner%2C%20B.%20M.%2C%20%26amp%3B%20Sederberg%2C%20P.%20B.%20%282020%29.%20A%20model%20of%20dynamic%2C%20within-trial%20conflict%20resolution%20for%20decision%20making.%20%26lt%3Bi%26gt%3BPsychological%20Review%26lt%3B%5C%2Fi%26gt%3B.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Frev0000191%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Frev0000191%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22A%20model%20of%20dynamic%2C%20within-trial%20conflict%20resolution%20for%20decision%20making.%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Emily%20R.%22%2C%22lastName%22%3A%22Weichart%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Brandon%20M.%22%2C%22lastName%22%3A%22Turner%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Per%20B.%22%2C%22lastName%22%3A%22Sederberg%22%7D%5D%2C%22abstractNote%22%3A%22Growing%20evidence%20for%20moment-to-moment%20fluctuations%20in%20visual%20attention%20has%20led%20to%20questions%20about%20the%20impetus%20and%20time%20course%20of%20cognitive%20control.%20These%20questions%20are%20typically%20investigated%20with%20paradigms%20like%20the%20flanker%20task%2C%20which%20require%20participants%20to%20inhibit%20an%20automatic%20response%20before%20making%20a%20decision.%20Connectionist%20modeling%20work%20suggests%20that%20between-trial%20changes%20in%20attention%20result%20from%20fluctuations%20in%20conflict%5Cu2014as%20conflict%20occurs%2C%20attention%20needs%20to%20be%20upregulated%20to%20resolve%20it.%20Current%20sequential%20sampling%20models%20%28SSMs%29%20of%20within-trial%20effects%2C%20however%2C%20suggest%20that%20attention%20focuses%20on%20a%20goal-relevant%20target%20as%20a%20function%20of%20time.%20We%20propose%20that%20within-trial%20changes%20in%20cognitive%20control%20and%20attention%20are%20emergent%20properties%20of%20the%20dynamics%20of%20the%20decision%20itself.%20We%20tested%20our%20hypothesis%20by%20developing%20a%20set%20of%20SSMs%2C%20each%20making%20alternative%20assumptions%20about%20attention%20modulation%20and%20evidence%20accumulation%20mechanisms.%20Combining%20the%20SSM%20framework%20with%20likelihood-free%20Bayesian%20approximation%20methods%20allowed%20us%20to%20conduct%20quantified%20comparisons%20between%20subject-level%20fits.%20Models%20included%20either%20time-%20or%20control-based%20attention%20mechanisms%2C%20and%20either%20strongly-%20%28via%20feedforward%20inhibition%29%20or%20weakly%20correlated%20%28via%20leak%20and%20lateral%20inhibition%29%20evidence%20accumulation%20mechanisms.%20We%20fit%20all%20models%20to%20behavioral%20data%20collected%20in%20variants%20of%20the%20flanker%20task%2C%20one%20accompanied%20by%20EEG%20measures.%20Across%20three%20experiments%2C%20we%20found%20converging%20evidence%20that%20control-based%20attention%20processes%20in%20combination%20with%20evidence%20accumulation%20mechanisms%20governed%20by%20leak%20and%20lateral%20inhibition%20provided%20the%20best%20fits%20to%20behavioral%20data%2C%20and%20uniquely%20mapped%20onto%20observed%20decision-related%20signals%20in%20the%20brain.%22%2C%22date%22%3A%222020-03-26%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1037%5C%2Frev0000191%22%2C%22ISSN%22%3A%221939-1471%2C%200033-295X%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fdoi.apa.org%5C%2Fgetdoi.cfm%3Fdoi%3D10.1037%5C%2Frev0000191%22%2C%22collections%22%3A%5B%22TT83T9T4%22%5D%2C%22dateModified%22%3A%222020-05-31T08%3A51%3A03Z%22%7D%7D%2C%7B%22key%22%3A%22RZMG6XNA%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Bates%20and%20Jacobs%22%2C%22parsedDate%22%3A%222020-04-23%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BBates%2C%20C.%20J.%2C%20%26amp%3B%20Jacobs%2C%20R.%20A.%20%282020%29.%20Efficient%20data%20compression%20in%20perception%20and%20perceptual%20memory.%20%26lt%3Bi%26gt%3BPsychological%20Review%26lt%3B%5C%2Fi%26gt%3B.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Frev0000197%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Frev0000197%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Efficient%20data%20compression%20in%20perception%20and%20perceptual%20memory.%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Christopher%20J.%22%2C%22lastName%22%3A%22Bates%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Robert%20A.%22%2C%22lastName%22%3A%22Jacobs%22%7D%5D%2C%22abstractNote%22%3A%22Efficient%20data%20compression%20is%20essential%20for%20capacity-limited%20systems%2C%20such%20as%20biological%20perception%20and%20perceptual%20memory.%20We%20hypothesize%20that%20the%20need%20for%20efficient%20compression%20shapes%20biological%20systems%20in%20many%20of%20the%20same%20ways%20that%20it%20shapes%20engineered%20systems.%20If%20true%2C%20then%20the%20tools%20that%20engineers%20use%20to%20analyze%20and%20design%20systems%2C%20namely%20rate-distortion%20theory%20%28RDT%29%2C%20can%20profitably%20be%20used%20to%20understand%20human%20perception%20and%20memory.%20The%20first%20portion%20of%20this%20article%20discusses%20how%20three%20general%20principles%20for%20efficient%20data%20compression%20provide%20accounts%20for%20many%20important%20behavioral%20phenomena%20and%20experimental%20results.%20We%20also%20discuss%20how%20these%20principles%20are%20embodied%20in%20RDT.%20The%20second%20portion%20notes%20that%20exact%20RDT%20methods%20are%20computationally%20feasible%20only%20in%20low-dimensional%20stimulus%20spaces.%20To%20date%2C%20researchers%20have%20used%20deep%20neural%20networks%20to%20approximately%20implement%20RDT%20in%20high-dimensional%20spaces%2C%20but%20these%20implementations%20have%20been%20limited%20to%20tasks%20in%20which%20the%20sole%20goal%20is%20compression%20with%20respect%20to%20reconstruction%20error.%20Here%2C%20we%20introduce%20a%20new%20deep%20neural%20network%20architecture%20that%20approximately%20implements%20RDT.%20An%20important%20property%20of%20our%20architecture%20is%20that%20it%20is%20trained%20%5Cu201cend-to-end%2C%5Cu201d%20operating%20on%20raw%20perceptual%20input%20%28e.g.%2C%20pixel%20values%29%20rather%20than%20intermediate%20levels%20of%20abstraction%2C%20as%20is%20the%20case%20with%20most%20psychological%20models.%20The%20article%5Cu2019s%20final%20portion%20conjectures%20on%20how%20efficient%20compression%20can%20occur%20in%20memory%20over%20time%2C%20thereby%20providing%20motivations%20for%20multiple%20memory%20systems%20operating%20at%20different%20time%20scales%2C%20and%20on%20how%20efficient%20compression%20may%20explain%20some%20attentional%20phenomena%20such%20as%20RTs%20in%20visual%20search.%22%2C%22date%22%3A%222020-04-23%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1037%5C%2Frev0000197%22%2C%22ISSN%22%3A%221939-1471%2C%200033-295X%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fdoi.apa.org%5C%2Fgetdoi.cfm%3Fdoi%3D10.1037%5C%2Frev0000197%22%2C%22collections%22%3A%5B%226X876M3T%22%5D%2C%22dateModified%22%3A%222020-05-31T08%3A43%3A20Z%22%7D%7D%2C%7B%22key%22%3A%22Q2JZYXWW%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Kvam%20and%20Busemeyer%22%2C%22parsedDate%22%3A%222020-05-28%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BKvam%2C%20P.%20D.%2C%20%26amp%3B%20Busemeyer%2C%20J.%20R.%20%282020%29.%20A%20distributional%20and%20dynamic%20theory%20of%20pricing%20and%20preference.%20%26lt%3Bi%26gt%3BPsychological%20Review%26lt%3B%5C%2Fi%26gt%3B.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Frev0000215%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1037%5C%2Frev0000215%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22A%20distributional%20and%20dynamic%20theory%20of%20pricing%20and%20preference.%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Peter%20D.%22%2C%22lastName%22%3A%22Kvam%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Jerome%20R.%22%2C%22lastName%22%3A%22Busemeyer%22%7D%5D%2C%22abstractNote%22%3A%22Theories%20that%20describe%20how%20people%20assign%20prices%20and%20make%20choices%20are%20typically%20based%20on%20the%20idea%20that%20both%20of%20these%20responses%20are%20derived%20from%20a%20common%20static%2C%20deterministic%20function%20used%20to%20assign%20utilities%20to%20options.%20However%2C%20preference%20reversals%5Cu2014where%20prices%20assigned%20to%20gambles%20conflict%20with%20preference%20orders%20elicited%20through%20binary%20choices%5Cu2014indicate%20that%20the%20response%20processes%20underlying%20these%20different%20methods%20of%20evaluation%20are%20more%20intricate.%20We%20address%20this%20issue%20by%20formulating%20a%20new%20computational%20model%20that%20assumes%20an%20initial%20bias%20or%20anchor%20that%20depends%20on%20type%20of%20price%20task%20%28buying%2C%20selling%2C%20or%20certainty%20equivalents%29%20and%20a%20stochastic%20evaluation%20accumulation%20process%20that%20depends%20on%20gamble%20attributes.%20To%20test%20this%20new%20model%2C%20we%20investigated%20choices%20and%20prices%20for%20a%20wide%20range%20of%20gambles%20and%20price%20tasks%2C%20including%20pricing%20under%20time%20pressure.%20In%20line%20with%20model%20predictions%2C%20we%20found%20that%20price%20distributions%20possessed%20stark%20skew%20that%20depended%20on%20the%20type%20of%20price%20and%20the%20attributes%20of%20gambles%20being%20considered.%20Prices%20were%20also%20sensitive%20to%20time%20pressure%2C%20indicating%20a%20dynamic%20evaluation%20process%20underlying%20price%20generation.%20The%20model%20out-performed%20prospect%20theory%20in%20predicting%20prices%20and%20additionally%20predicted%20the%20response%20times%20associated%20with%20these%20prices%2C%20which%20no%20prior%20model%20has%20accomplished.%20Finally%2C%20we%20show%20that%20the%20model%20successfully%20predicts%20out-of-sample%20choices%20and%20that%20its%20parameters%20allow%20us%20to%20fit%20choice%20response%20times%20as%20well.%20This%20price%20accumulation%20model%20therefore%20provides%20a%20superior%20account%20of%20the%20distributional%20and%20dynamic%20properties%20of%20price%2C%20leveraging%20process-level%20mechanisms%20to%20provide%20a%20more%20complete%20account%20of%20the%20valuation%20processes%20common%20across%20multiple%20methods%20of%20eliciting%20preference.%22%2C%22date%22%3A%222020-05-28%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1037%5C%2Frev0000215%22%2C%22ISSN%22%3A%221939-1471%2C%200033-295X%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fdoi.apa.org%5C%2Fgetdoi.cfm%3Fdoi%3D10.1037%5C%2Frev0000215%22%2C%22collections%22%3A%5B%22IFJ5FWUK%22%5D%2C%22dateModified%22%3A%222020-05-31T08%3A42%3A57Z%22%7D%7D%2C%7B%22key%22%3A%228SNRMJBY%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Blundell%20et%20al.%22%2C%22parsedDate%22%3A%222012%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BBlundell%2C%20C.%2C%20Sanborn%2C%20A.%2C%20%26amp%3B%20Grif%26%23xFB01%3Bths%2C%20T.%20L.%20%282012%29.%20Look-Ahead%20Monte%20Carlo%20with%20People%20%28p.%207%29.%20Presented%20at%20the%20Proceedings%20of%20the%20Annual%20Meeting%20of%20the%20Cognitive%20Science%20Society.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22Look-Ahead%20Monte%20Carlo%20with%20People%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Charles%22%2C%22lastName%22%3A%22Blundell%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adam%22%2C%22lastName%22%3A%22Sanborn%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Thomas%20L%22%2C%22lastName%22%3A%22Grif%5Cufb01ths%22%7D%5D%2C%22abstractNote%22%3A%22Investigating%20people%5Cu2019s%20representations%20of%20categories%20of%20complicated%20objects%20is%20a%20dif%5Cufb01cult%20challenge%2C%20not%20least%20because%20of%20the%20large%20number%20of%20ways%20in%20which%20such%20objects%20can%20vary.%20To%20make%20progress%20we%20need%20to%20take%20advantage%20of%20the%20structure%20of%20object%20categories%20%5Cu2013%20one%20compelling%20regularity%20is%20that%20object%20categories%20can%20be%20described%20by%20a%20small%20number%20of%20dimensions.%20We%20present%20Look-Ahead%20Monte%20Carlo%20with%20People%2C%20a%20method%20for%20exploring%20people%5Cu2019s%20representations%20of%20a%20category%20where%20there%20are%20many%20irrelevant%20dimensions.%20This%20method%20combines%20ideas%20from%20Markov%20chain%20Monte%20Carlo%20with%20People%2C%20an%20experimental%20paradigm%20derived%20from%20an%20algorithm%20for%20sampling%20complicated%20distributions%2C%20with%20hybrid%20Monte%20Carlo%2C%20a%20technique%20that%20uses%20directional%20information%20to%20construct%20ef%5Cufb01cient%20statistical%20sampling%20algorithms.%20We%20show%20that%20even%20in%20a%20simple%20example%2C%20our%20approach%20takes%20advantage%20of%20the%20structure%20of%20object%20categories%20to%20make%20experiments%20shorter%20and%20increase%20our%20ability%20to%20accurately%20estimate%20category%20representations.%22%2C%22date%22%3A%222012%22%2C%22proceedingsTitle%22%3A%22%22%2C%22conferenceName%22%3A%22Proceedings%20of%20the%20Annual%20Meeting%20of%20the%20Cognitive%20Science%20Society%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22M58FE8CG%22%5D%2C%22dateModified%22%3A%222020-05-30T08%3A19%3A53Z%22%7D%7D%2C%7B%22key%22%3A%22G9C2YJ3F%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Leon-Villagra%20et%20al.%22%2C%22parsedDate%22%3A%222020%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BLeon-Villagra%2C%20P.%2C%20Otsubo%2C%20K.%2C%20Lucas%2C%20C.%20G.%2C%20%26amp%3B%20Buchsbaum%2C%20D.%20%282020%29.%20Uncovering%20Category%20Representations%20with%20Linked%20MCMC%20with%20people.%20In%20%26lt%3Bi%26gt%3BProceedings%20of%20the%20Annual%20Meeting%20of%20the%20Cognitive%20Science%20Society%26lt%3B%5C%2Fi%26gt%3B%20%28p.%207%29.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22Uncovering%20Category%20Representations%20with%20Linked%20MCMC%20with%20people%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Pablo%22%2C%22lastName%22%3A%22Leon-Villagra%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Kay%22%2C%22lastName%22%3A%22Otsubo%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Christopher%20G%22%2C%22lastName%22%3A%22Lucas%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Daphna%22%2C%22lastName%22%3A%22Buchsbaum%22%7D%5D%2C%22abstractNote%22%3A%22Cognitive%20science%20is%20often%20concerned%20with%20questions%20about%20our%20representations%20of%20concepts%20and%20the%20underlying%20psychological%20spaces%20in%20which%20these%20concepts%20are%20embedded.%20One%20method%20to%20reveal%20concepts%20and%20conceptual%20spaces%20experimentally%20is%20Markov%20chain%20Monte%20Carlo%20with%20people%20%28MCMCP%29%2C%20where%20participants%20produce%20samples%20from%20their%20implicit%20categories.%20While%20MCMCP%20has%20allowed%20for%20the%20experimental%20study%20of%20psychological%20representations%20of%20complex%20categories%2C%20experiments%20are%20typically%20long%20and%20repetitive.%20Here%2C%20we%20contrasted%20the%20classical%20MCMCP%20design%20with%20a%20linked%20variant%2C%20in%20which%20each%20participant%20completed%20just%20a%20short%20run%20of%20MCMCP%20trials%2C%20which%20were%20then%20combined%20to%20produce%20a%20single%20sample%20set.%20We%20found%20that%20linking%20produced%20results%20that%20were%20nearly%20indistinguishable%20from%20classical%20MCMCP%2C%20and%20often%20converged%20to%20the%20desired%20distribution%20faster.%20Our%20results%20support%20linking%20as%20an%20approach%20for%20performing%20MCMCP%20experiments%20within%20broader%20populations%2C%20such%20as%20in%20developmental%20settings%20where%20large%20numbers%20of%20trials%20per%20participant%20are%20impractical.%22%2C%22date%22%3A%222020%22%2C%22proceedingsTitle%22%3A%22Proceedings%20of%20the%20Annual%20Meeting%20of%20the%20Cognitive%20Science%20Society%22%2C%22conferenceName%22%3A%22%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22M58FE8CG%22%5D%2C%22dateModified%22%3A%222020-05-30T08%3A18%3A25Z%22%7D%7D%2C%7B%22key%22%3A%227LIMBADE%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Leon-Villagra%20et%20al.%22%2C%22parsedDate%22%3A%222019%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BLeon-Villagra%2C%20P.%2C%20Klar%2C%20V.%20S.%2C%20Sanborn%2C%20A.%20N.%2C%20%26amp%3B%20Lucas%2C%20C.%20G.%20%282019%29.%20Exploring%20the%20Representation%20of%20Linear%20Functions.%20In%20%26lt%3Bi%26gt%3BProceedings%20of%20the%20Annual%20Meeting%20of%20the%20Cognitive%20Science%20Society%26lt%3B%5C%2Fi%26gt%3B%20%28p.%207%29.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22Exploring%20the%20Representation%20of%20Linear%20Functions%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Pablo%22%2C%22lastName%22%3A%22Leon-Villagra%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Verena%20S%22%2C%22lastName%22%3A%22Klar%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adam%20N%22%2C%22lastName%22%3A%22Sanborn%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Christopher%20G%22%2C%22lastName%22%3A%22Lucas%22%7D%5D%2C%22abstractNote%22%3A%22Function%20learning%20research%20has%20highlighted%20the%20importance%20of%20human%20inductive%20biases%20that%20facilitate%20long-range%20extrapolations.%20However%2C%20most%20previous%20research%20is%20focused%20on%20aggregate%20errors%20or%20single-criterion%20extrapolations.%20Thus%2C%20little%20is%20known%20about%20the%20underlying%20psychological%20space%20in%20which%20continuous%20relationships%20are%20represented.%20We%20ask%20whether%20people%20can%20learn%20the%20distributional%20properties%20of%20new%20classes%20of%20relationships%2C%20using%20Markov%20Chain%20Monte%20Carlo%20with%20People%2C%20and%20%5Cufb01nd%20that%20%281%29%20people%20are%20able%20to%20track%20not%20just%20the%20expected%20parameters%20of%20a%20linear%20function%2C%20but%20information%20about%20the%20variability%20of%20functions%20in%20a%20speci%5Cufb01c%20context%20and%20%282%29%20in%20many%20cases%20these%20spaces%20over%20parameters%20exhibit%20multiple%20modes.%22%2C%22date%22%3A%222019%22%2C%22proceedingsTitle%22%3A%22Proceedings%20of%20the%20Annual%20Meeting%20of%20the%20Cognitive%20Science%20Society%22%2C%22conferenceName%22%3A%22%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22M58FE8CG%22%5D%2C%22dateModified%22%3A%222020-05-30T08%3A18%3A19Z%22%7D%7D%2C%7B%22key%22%3A%22UKFNZ8B2%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Ramlee%20et%20al.%22%2C%22parsedDate%22%3A%222017-07-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BRamlee%2C%20F.%2C%20Sanborn%2C%20A.%20N.%2C%20%26amp%3B%20Tang%2C%20N.%20K.%20Y.%20%282017%29.%20What%20Sways%20People%26%23x2019%3Bs%20Judgment%20of%20Sleep%20Quality%3F%20A%20Quantitative%20Choice-Making%20Study%20With%20Good%20and%20Poor%20Sleepers.%20%26lt%3Bi%26gt%3BSleep%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B40%26lt%3B%5C%2Fi%26gt%3B%287%29.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1093%5C%2Fsleep%5C%2Fzsx091%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1093%5C%2Fsleep%5C%2Fzsx091%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22What%20Sways%20People%5Cu2019s%20Judgment%20of%20Sleep%20Quality%3F%20A%20Quantitative%20Choice-Making%20Study%20With%20Good%20and%20Poor%20Sleepers%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Fatanah%22%2C%22lastName%22%3A%22Ramlee%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adam%20N.%22%2C%22lastName%22%3A%22Sanborn%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Nicole%20K.%20Y.%22%2C%22lastName%22%3A%22Tang%22%7D%5D%2C%22abstractNote%22%3A%22AbstractStudy%20objectives%3A.%20%20We%20conceptualized%20sleep%20quality%20judgment%20as%20a%20decision-making%20process%20and%20examined%20the%20relative%20importance%20of%2017%20parameters%20of%20sleep%22%2C%22date%22%3A%222017%5C%2F07%5C%2F01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1093%5C%2Fsleep%5C%2Fzsx091%22%2C%22ISSN%22%3A%220161-8105%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Facademic.oup.com%5C%2Fsleep%5C%2Farticle%5C%2F40%5C%2F7%5C%2Fzsx091%5C%2F3835259%22%2C%22collections%22%3A%5B%22M58FE8CG%22%5D%2C%22dateModified%22%3A%222020-05-30T08%3A17%3A20Z%22%7D%7D%2C%7B%22key%22%3A%22I4P368RF%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Hsu%20et%20al.%22%2C%22parsedDate%22%3A%222019-08-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BHsu%2C%20A.%20S.%2C%20Martin%2C%20J.%20B.%2C%20Sanborn%2C%20A.%20N.%2C%20%26amp%3B%20Griffiths%2C%20T.%20L.%20%282019%29.%20Identifying%20category%20representations%20for%20complex%20stimuli%20using%20discrete%20Markov%20chain%20Monte%20Carlo%20with%20people.%20%26lt%3Bi%26gt%3BBehavior%20Research%20Methods%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B51%26lt%3B%5C%2Fi%26gt%3B%284%29%2C%201706%26%23x2013%3B1716.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13428-019-01201-9%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13428-019-01201-9%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Identifying%20category%20representations%20for%20complex%20stimuli%20using%20discrete%20Markov%20chain%20Monte%20Carlo%20with%20people%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Anne%20S.%22%2C%22lastName%22%3A%22Hsu%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Jay%20B.%22%2C%22lastName%22%3A%22Martin%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adam%20N.%22%2C%22lastName%22%3A%22Sanborn%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Thomas%20L.%22%2C%22lastName%22%3A%22Griffiths%22%7D%5D%2C%22abstractNote%22%3A%22With%20the%20explosion%20of%20%5Cu201cbig%20data%2C%5Cu201d%20digital%20repositories%20of%20texts%20and%20images%20are%20growing%20rapidly.%20These%20datasets%20present%20new%20opportunities%20for%20psychological%20research%2C%20but%20they%20require%20new%20methodologies%20before%20researchers%20can%20use%20these%20datasets%20to%20yield%20insights%20into%20human%20cognition.%20We%20present%20a%20new%20method%20that%20allows%20psychological%20researchers%20to%20take%20advantage%20of%20text%20and%20image%20databases%3A%20a%20procedure%20for%20measuring%20human%20categorical%20representations%20over%20large%20datasets%20of%20items%2C%20such%20as%20arbitrary%20words%20or%20pictures.%20We%20call%20this%20method%20discrete%20Markov%20chain%20Monte%20Carlo%20with%20people%20%28d-MCMCP%29.%20We%20illustrate%20our%20method%20by%20evaluating%20the%20following%20categories%20over%20datasets%3A%20emotions%20as%20represented%20by%20facial%20images%2C%20moral%20concepts%20as%20represented%20by%20relevant%20words%2C%20and%20seasons%20as%20represented%20by%20images%20drawn%20from%20large%20online%20databases.%20Three%20experiments%20demonstrate%20that%20d-MCMCP%20is%20powerful%20and%20flexible%20enough%20to%20work%20with%20complex%2C%20naturalistic%20stimuli%20drawn%20from%20large%20online%20databases.%22%2C%22date%22%3A%222019-08-01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.3758%5C%2Fs13428-019-01201-9%22%2C%22ISSN%22%3A%221554-3528%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13428-019-01201-9%22%2C%22collections%22%3A%5B%22M58FE8CG%22%5D%2C%22dateModified%22%3A%222020-05-30T08%3A16%3A32Z%22%7D%7D%2C%7B%22key%22%3A%22JZYW638U%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Martin%20et%20al.%22%2C%22parsedDate%22%3A%222012%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BMartin%2C%20J.%20B.%2C%20Griffiths%2C%20T.%20L.%2C%20%26amp%3B%20Sanborn%2C%20A.%20N.%20%282012%29.%20Testing%20the%20Efficiency%20of%20Markov%20Chain%20Monte%20Carlo%20With%20People%20Using%20Facial%20Affect%20Categories.%20%26lt%3Bi%26gt%3BCognitive%20Science%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B36%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%20150%26%23x2013%3B162.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1111%5C%2Fj.1551-6709.2011.01204.x%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1111%5C%2Fj.1551-6709.2011.01204.x%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Testing%20the%20Efficiency%20of%20Markov%20Chain%20Monte%20Carlo%20With%20People%20Using%20Facial%20Affect%20Categories%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Jay%20B.%22%2C%22lastName%22%3A%22Martin%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Thomas%20L.%22%2C%22lastName%22%3A%22Griffiths%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adam%20N.%22%2C%22lastName%22%3A%22Sanborn%22%7D%5D%2C%22abstractNote%22%3A%22Exploring%20how%20people%20represent%20natural%20categories%20is%20a%20key%20step%20toward%20developing%20a%20better%20understanding%20of%20how%20people%20learn%2C%20form%20memories%2C%20and%20make%20decisions.%20Much%20research%20on%20categorization%20has%20focused%20on%20artificial%20categories%20that%20are%20created%20in%20the%20laboratory%2C%20since%20studying%20natural%20categories%20defined%20on%20high-dimensional%20stimuli%20such%20as%20images%20is%20methodologically%20challenging.%20Recent%20work%20has%20produced%20methods%20for%20identifying%20these%20representations%20from%20observed%20behavior%2C%20such%20as%20reverse%20correlation%20%28RC%29.%20We%20compare%20RC%20against%20an%20alternative%20method%20for%20inferring%20the%20structure%20of%20natural%20categories%20called%20Markov%20chain%20Monte%20Carlo%20with%20People%20%28MCMCP%29.%20Based%20on%20an%20algorithm%20used%20in%20computer%20science%20and%20statistics%2C%20MCMCP%20provides%20a%20way%20to%20sample%20from%20the%20set%20of%20stimuli%20associated%20with%20a%20natural%20category.%20We%20apply%20MCMCP%20and%20RC%20to%20the%20problem%20of%20recovering%20natural%20categories%20that%20correspond%20to%20two%20kinds%20of%20facial%20affect%20%28happy%20and%20sad%29%20from%20realistic%20images%20of%20faces.%20Our%20results%20show%20that%20MCMCP%20requires%20fewer%20trials%20to%20obtain%20a%20higher%20quality%20estimate%20of%20people%5Cu2019s%20mental%20representations%20of%20these%20two%20categories.%22%2C%22date%22%3A%222012%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1111%5C%2Fj.1551-6709.2011.01204.x%22%2C%22ISSN%22%3A%221551-6709%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fonlinelibrary.wiley.com%5C%2Fdoi%5C%2Fabs%5C%2F10.1111%5C%2Fj.1551-6709.2011.01204.x%22%2C%22collections%22%3A%5B%22M58FE8CG%22%5D%2C%22dateModified%22%3A%222020-05-30T08%3A14%3A52Z%22%7D%7D%2C%7B%22key%22%3A%22IW8GDEUL%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Gronau%20et%20al.%22%2C%22parsedDate%22%3A%222019-03-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BGronau%2C%20Q.%20F.%2C%20Wagenmakers%2C%20E.-J.%2C%20Heck%2C%20D.%20W.%2C%20%26amp%3B%20Matzke%2C%20D.%20%282019%29.%20A%20Simple%20Method%20for%20Comparing%20Complex%20Models%3A%20Bayesian%20Model%20Comparison%20for%20Hierarchical%20Multinomial%20Processing%20Tree%20Models%20Using%20Warp-III%20Bridge%20Sampling.%20%26lt%3Bi%26gt%3BPsychometrika%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B84%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%20261%26%23x2013%3B284.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs11336-018-9648-3%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs11336-018-9648-3%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22A%20Simple%20Method%20for%20Comparing%20Complex%20Models%3A%20Bayesian%20Model%20Comparison%20for%20Hierarchical%20Multinomial%20Processing%20Tree%20Models%20Using%20Warp-III%20Bridge%20Sampling%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Quentin%20F.%22%2C%22lastName%22%3A%22Gronau%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Eric-Jan%22%2C%22lastName%22%3A%22Wagenmakers%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Daniel%20W.%22%2C%22lastName%22%3A%22Heck%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Dora%22%2C%22lastName%22%3A%22Matzke%22%7D%5D%2C%22abstractNote%22%3A%22Multinomial%20processing%20trees%20%28MPTs%29%20are%20a%20popular%20class%20of%20cognitive%20models%20for%20categorical%20data.%20Typically%2C%20researchers%20compare%20several%20MPTs%2C%20each%20equipped%20with%20many%20parameters%2C%20especially%20when%20the%20models%20are%20implemented%20in%20a%20hierarchical%20framework.%20A%20Bayesian%20solution%20is%20to%20compute%20posterior%20model%20probabilities%20and%20Bayes%20factors.%20Both%20quantities%2C%20however%2C%20rely%20on%20the%20marginal%20likelihood%2C%20a%20high-dimensional%20integral%20that%20cannot%20be%20evaluated%20analytically.%20In%20this%20case%20study%2C%20we%20show%20how%20Warp-III%20bridge%20sampling%20can%20be%20used%20to%20compute%20the%20marginal%20likelihood%20for%20hierarchical%20MPTs.%20We%20illustrate%20the%20procedure%20with%20two%20published%20data%20sets%20and%20demonstrate%20how%20Warp-III%20facilitates%20Bayesian%20model%20averaging.%22%2C%22date%22%3A%222019-03-01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1007%5C%2Fs11336-018-9648-3%22%2C%22ISSN%22%3A%221860-0980%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs11336-018-9648-3%22%2C%22collections%22%3A%5B%224TRVT3PR%22%5D%2C%22dateModified%22%3A%222020-05-28T18%3A23%3A25Z%22%7D%7D%2C%7B%22key%22%3A%22G65UIJK3%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Wickelmaier%20and%20Zeileis%22%2C%22parsedDate%22%3A%222018-06-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BWickelmaier%2C%20F.%2C%20%26amp%3B%20Zeileis%2C%20A.%20%282018%29.%20Using%20recursive%20partitioning%20to%20account%20for%20parameter%20heterogeneity%20in%20multinomial%20processing%20tree%20models.%20%26lt%3Bi%26gt%3BBehavior%20Research%20Methods%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B50%26lt%3B%5C%2Fi%26gt%3B%283%29%2C%201217%26%23x2013%3B1233.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13428-017-0937-z%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13428-017-0937-z%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Using%20recursive%20partitioning%20to%20account%20for%20parameter%20heterogeneity%20in%20multinomial%20processing%20tree%20models%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Florian%22%2C%22lastName%22%3A%22Wickelmaier%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Achim%22%2C%22lastName%22%3A%22Zeileis%22%7D%5D%2C%22abstractNote%22%3A%22In%20multinomial%20processing%20tree%20%28MPT%29%20models%2C%20individual%20differences%20between%20the%20participants%20in%20a%20study%20can%20lead%20to%20heterogeneity%20of%20the%20model%20parameters.%20While%20subject%20covariates%20may%20explain%20these%20differences%2C%20it%20is%20often%20unknown%20in%20advance%20how%20the%20parameters%20depend%20on%20the%20available%20covariates%2C%20that%20is%2C%20which%20variables%20play%20a%20role%20at%20all%2C%20interact%2C%20or%20have%20a%20nonlinear%20influence%2C%20etc.%20Therefore%2C%20a%20new%20approach%20for%20capturing%20parameter%20heterogeneity%20in%20MPT%20models%20is%20proposed%20based%20on%20the%20machine%20learning%20method%20MOB%20for%20model-based%20recursive%20partitioning.%20This%20procedure%20recursively%20partitions%20the%20covariate%20space%2C%20leading%20to%20an%20MPT%20tree%20with%20subgroups%20that%20are%20directly%20interpretable%20in%20terms%20of%20effects%20and%20interactions%20of%20the%20covariates.%20The%20pros%20and%20cons%20of%20MPT%20trees%20as%20a%20means%20of%20analyzing%20the%20effects%20of%20covariates%20in%20MPT%20model%20parameters%20are%20discussed%20based%20on%20simulation%20experiments%20as%20well%20as%20on%20two%20empirical%20applications%20from%20memory%20research.%20Software%20that%20implements%20MPT%20trees%20is%20provided%20via%20the%20mpttree%20function%20in%20the%20psychotree%20package%20in%20R.%22%2C%22date%22%3A%222018-06-01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.3758%5C%2Fs13428-017-0937-z%22%2C%22ISSN%22%3A%221554-3528%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.3758%5C%2Fs13428-017-0937-z%22%2C%22collections%22%3A%5B%224TRVT3PR%22%5D%2C%22dateModified%22%3A%222020-05-28T14%3A33%3A28Z%22%7D%7D%2C%7B%22key%22%3A%22HL3R7284%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Jacobucci%20and%20Grimm%22%2C%22parsedDate%22%3A%222018-07-04%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BJacobucci%2C%20R.%2C%20%26amp%3B%20Grimm%2C%20K.%20J.%20%282018%29.%20Comparison%20of%20Frequentist%20and%20Bayesian%20Regularization%20in%20Structural%20Equation%20Modeling.%20%26lt%3Bi%26gt%3BStructural%20Equation%20Modeling%3A%20A%20Multidisciplinary%20Journal%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B25%26lt%3B%5C%2Fi%26gt%3B%284%29%2C%20639%26%23x2013%3B649.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2017.1410822%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2017.1410822%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Comparison%20of%20Frequentist%20and%20Bayesian%20Regularization%20in%20Structural%20Equation%20Modeling%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Ross%22%2C%22lastName%22%3A%22Jacobucci%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Kevin%20J.%22%2C%22lastName%22%3A%22Grimm%22%7D%5D%2C%22abstractNote%22%3A%22Research%20in%20regularization%2C%20as%20applied%20to%20structural%20equation%20modeling%20%28SEM%29%2C%20remains%20in%20its%20infancy.%20Specifically%2C%20very%20little%20work%20has%20compared%20regularization%20approaches%20across%20both%20frequentist%20and%20Bayesian%20estimation.%20The%20purpose%20of%20this%20study%20was%20to%20address%20just%20that%2C%20demonstrating%20both%20similarity%20and%20distinction%20across%20estimation%20frameworks%2C%20while%20specifically%20highlighting%20more%20recent%20developments%20in%20Bayesian%20regularization.%20This%20is%20accomplished%20through%20the%20use%20of%20two%20empirical%20examples%20that%20demonstrate%20both%20ridge%20and%20lasso%20approaches%20across%20both%20frequentist%20and%20Bayesian%20estimation%2C%20along%20with%20detail%20regarding%20software%20implementation.%20We%20conclude%20with%20a%20discussion%20of%20future%20research%2C%20advocating%20for%20increased%20evaluation%20and%20synthesis%20across%20both%20Bayesian%20and%20frequentist%20frameworks.%22%2C%22date%22%3A%22July%204%2C%202018%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%2210.1080%5C%2F10705511.2017.1410822%22%2C%22ISSN%22%3A%221070-5511%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2017.1410822%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-28T12%3A17%3A49Z%22%7D%7D%2C%7B%22key%22%3A%22BBQ62YYL%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Raftery%22%2C%22parsedDate%22%3A%221993%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BRaftery%2C%20A.%20E.%20%281993%29.%20Bayesian%20model%20selection%20in%20structural%20equation%20models.%20In%20K.%20A.%20Bollen%20%26amp%3B%20J.%20S.%20Long%20%28Eds.%29%2C%20%26lt%3Bi%26gt%3BTesting%20Structural%20Equation%20Models%26lt%3B%5C%2Fi%26gt%3B%20%28pp.%20163%26%23x2013%3B180%29.%20Beverly%20Hills%3A%20SAGE%20Publications.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22bookSection%22%2C%22title%22%3A%22Bayesian%20model%20selection%20in%20structural%20equation%20models%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adrian%20E%22%2C%22lastName%22%3A%22Raftery%22%7D%2C%7B%22creatorType%22%3A%22editor%22%2C%22firstName%22%3A%22Kenneth%20A.%22%2C%22lastName%22%3A%22Bollen%22%7D%2C%7B%22creatorType%22%3A%22editor%22%2C%22firstName%22%3A%22J.%20Scott%22%2C%22lastName%22%3A%22Long%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22bookTitle%22%3A%22Testing%20Structural%20Equation%20Models%22%2C%22date%22%3A%221993%22%2C%22language%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-27T17%3A18%3A48Z%22%7D%7D%2C%7B%22key%22%3A%22G4P8HD2E%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Lewis%20and%20Raftery%22%2C%22parsedDate%22%3A%221997%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BLewis%2C%20S.%20M.%2C%20%26amp%3B%20Raftery%2C%20A.%20E.%20%281997%29.%20Estimating%20Bayes%20Factors%20via%20Posterior%20Simulation%20With%20the%20Laplace-Metropolis%20Estimator.%20%26lt%3Bi%26gt%3BJournal%20of%20the%20American%20Statistical%20Association%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B92%26lt%3B%5C%2Fi%26gt%3B%28438%29%2C%20648%26%23x2013%3B655.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.2307%5C%2F2965712%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.2307%5C%2F2965712%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Estimating%20Bayes%20Factors%20via%20Posterior%20Simulation%20With%20the%20Laplace-Metropolis%20Estimator%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Steven%20M.%22%2C%22lastName%22%3A%22Lewis%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Adrian%20E.%22%2C%22lastName%22%3A%22Raftery%22%7D%5D%2C%22abstractNote%22%3A%22The%20key%20quantity%20needed%20for%20Bayesian%20hypothesis%20testing%20and%20model%20selection%20is%20the%20integrated%2C%20or%20marginal%2C%20likelihood%20of%20a%20model.%20We%20describe%20a%20way%20to%20use%20posterior%20simulation%20output%20to%20estimate%20integrated%20likelihoods.%20We%20describe%20the%20basic%20Laplace--Metropolis%20estimator%20for%20models%20without%20random%20effects.%20For%20models%20with%20random%20effects%2C%20we%20introduce%20the%20compound%20Laplace-Metropolis%20estimator.%20We%20apply%20this%20estimator%20to%20data%20from%20the%20World%20Fertility%20Survey%20and%20show%20it%20to%20give%20accurate%20results.%20Batching%20of%20simulation%20output%20is%20used%20to%20assess%20the%20uncertainty%20involved%20in%20using%20the%20compound%20Laplace-Metropolis%20estimator.%20The%20method%20allows%20us%20to%20test%20for%20the%20effects%20of%20independent%20variables%20in%20a%20random-effects%20model%20and%20also%20to%20test%20for%20the%20presence%20of%20the%20random%20effects.%22%2C%22date%22%3A%221997%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%2210.2307%5C%2F2965712%22%2C%22ISSN%22%3A%220162-1459%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fwww.jstor.org%5C%2Fstable%5C%2F2965712%22%2C%22collections%22%3A%5B%2232HV3NV5%22%5D%2C%22dateModified%22%3A%222020-05-27T12%3A52%3A04Z%22%7D%7D%2C%7B%22key%22%3A%22PNIY2UMF%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Mair%22%2C%22parsedDate%22%3A%222018%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BMair%2C%20P.%20%282018%29.%20%26lt%3Bi%26gt%3BModern%20psychometrics%20with%20R%26lt%3B%5C%2Fi%26gt%3B.%20Cham%2C%20Switzerland%3A%20Springer.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22book%22%2C%22title%22%3A%22Modern%20psychometrics%20with%20R%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Patrick%22%2C%22lastName%22%3A%22Mair%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222018%22%2C%22language%22%3A%22eng%22%2C%22ISBN%22%3A%22978-3-319-93177-7%20978-3-319-93175-3%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-27T12%3A41%3A42Z%22%7D%7D%2C%7B%22key%22%3A%224SDPCPYU%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Rosseel%22%2C%22parsedDate%22%3A%222012-05-24%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BRosseel%2C%20Y.%20%282012%29.%20lavaan%3A%20An%20R%20Package%20for%20Structural%20Equation%20Modeling.%20%26lt%3Bi%26gt%3BJournal%20of%20Statistical%20Software%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B48%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%201%26%23x2013%3B36.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.18637%5C%2Fjss.v048.i02%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.18637%5C%2Fjss.v048.i02%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22lavaan%3A%20An%20R%20Package%20for%20Structural%20Equation%20Modeling%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Yves%22%2C%22lastName%22%3A%22Rosseel%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222012%5C%2F05%5C%2F24%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.18637%5C%2Fjss.v048.i02%22%2C%22ISSN%22%3A%221548-7660%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fwww.jstatsoft.org%5C%2Findex.php%5C%2Fjss%5C%2Farticle%5C%2Fview%5C%2Fv048i02%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T20%3A13%3A16Z%22%7D%7D%2C%7B%22key%22%3A%22XA9752IN%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Kaplan%20and%20Lee%22%2C%22parsedDate%22%3A%222016-05-03%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BKaplan%2C%20D.%2C%20%26amp%3B%20Lee%2C%20C.%20%282016%29.%20Bayesian%20Model%20Averaging%20Over%20Directed%20Acyclic%20Graphs%20With%20Implications%20for%20the%20Predictive%20Performance%20of%20Structural%20Equation%20Models.%20%26lt%3Bi%26gt%3BStructural%20Equation%20Modeling%3A%20A%20Multidisciplinary%20Journal%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B23%26lt%3B%5C%2Fi%26gt%3B%283%29%2C%20343%26%23x2013%3B353.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-DOIURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2015.1092088%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2015.1092088%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Bayesian%20Model%20Averaging%20Over%20Directed%20Acyclic%20Graphs%20With%20Implications%20for%20the%20Predictive%20Performance%20of%20Structural%20Equation%20Models%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22David%22%2C%22lastName%22%3A%22Kaplan%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Chansoon%22%2C%22lastName%22%3A%22Lee%22%7D%5D%2C%22abstractNote%22%3A%22This%20article%20examines%20Bayesian%20model%20averaging%20as%20a%20means%20of%20addressing%20predictive%20performance%20in%20Bayesian%20structural%20equation%20models.%20The%20current%20approach%20to%20addressing%20the%20problem%20of%20model%20uncertainty%20lies%20in%20the%20method%20of%20Bayesian%20model%20averaging.%20We%20expand%20the%20work%20of%20Madigan%20and%20his%20colleagues%20by%20considering%20a%20structural%20equation%20model%20as%20a%20special%20case%20of%20a%20directed%20acyclic%20graph.%20We%20then%20provide%20an%20algorithm%20that%20searches%20the%20model%20space%20for%20submodels%20and%20obtains%20a%20weighted%20average%20of%20the%20submodels%20using%20posterior%20model%20probabilities%20as%20weights.%20Our%20simulation%20study%20provides%20a%20frequentist%20evaluation%20of%20our%20Bayesian%20model%20averaging%20approach%20and%20indicates%20that%20when%20the%20true%20model%20is%20known%2C%20Bayesian%20model%20averaging%20does%20not%20yield%20necessarily%20better%20predictive%20performance%20compared%20to%20nonaveraged%20models.%20However%2C%20our%20case%20study%20using%20data%20from%20an%20international%20large-scale%20assessment%20reveals%20that%20the%20model-averaged%20submodels%20provide%20better%20posterior%20predictive%20performance%20compared%20to%20the%20initially%20speci%5Cufb01ed%20model.%22%2C%22date%22%3A%222016-05-03%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1080%5C%2F10705511.2015.1092088%22%2C%22ISSN%22%3A%221070-5511%2C%201532-8007%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.tandfonline.com%5C%2Fdoi%5C%2Ffull%5C%2F10.1080%5C%2F10705511.2015.1092088%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T20%3A03%3A34Z%22%7D%7D%2C%7B%22key%22%3A%22EF8VZD87%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Schoot%20et%20al.%22%2C%22parsedDate%22%3A%222013-01-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BSchoot%2C%20R.%20van%20de%2C%20Verhoeven%2C%20M.%2C%20%26amp%3B%20Hoijtink%2C%20H.%20%282013%29.%20Bayesian%20evaluation%20of%20informative%20hypotheses%20in%20SEM%20using%20Mplus%3A%20A%20black%20bear%20story.%20%26lt%3Bi%26gt%3BEuropean%20Journal%20of%20Developmental%20Psychology%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B10%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%2081%26%23x2013%3B98.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F17405629.2012.732719%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F17405629.2012.732719%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Bayesian%20evaluation%20of%20informative%20hypotheses%20in%20SEM%20using%20Mplus%3A%20A%20black%20bear%20story%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Rens%20van%20de%22%2C%22lastName%22%3A%22Schoot%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Marjolein%22%2C%22lastName%22%3A%22Verhoeven%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Herbert%22%2C%22lastName%22%3A%22Hoijtink%22%7D%5D%2C%22abstractNote%22%3A%22Half%20in%20jest%20we%20use%20a%20story%20about%20a%20black%20bear%20to%20illustrate%20that%20there%20are%20some%20discrepancies%20between%20the%20formal%20use%20of%20the%20p-value%20and%20the%20way%20it%20is%20often%20used%20in%20practice.%20We%20argue%20that%20more%20can%20be%20learned%20from%20data%20by%20evaluating%20informative%20hypotheses%2C%20than%20by%20testing%20the%20traditional%20null%20hypothesis.%20All%20criticisms%20of%20classical%20null%20hypothesis%20testing%20aside%2C%20the%20best%20argument%20for%20evaluating%20informative%20hypotheses%20is%20that%20many%20researchers%20want%20to%20evaluate%20their%20expectations%20directly%2C%20but%20have%20been%20unable%20to%20do%20so%20because%20the%20statistical%20tools%20were%20not%20yet%20available.%20It%20will%20be%20shown%20that%20a%20Bayesian%20model%20selection%20procedure%20can%20be%20used%20to%20evaluate%20informative%20hypotheses%20in%20structural%20equation%20models%20using%20the%20software%20Mplus.%20In%20the%20current%20paper%20we%20introduce%20the%20methodology%20using%20a%20real-life%20example%20taken%20from%20the%20field%20of%20developmental%20psychology%20about%20depressive%20symptoms%20in%20adolescence%20and%20provide%20a%20step-by-step%20description%20so%20that%20the%20procedure%20becomes%20more%20comprehensible%20for%20applied%20researchers.%20As%20this%20paper%20illustrates%2C%20this%20methodology%20is%20ready%20to%20be%20used%20by%20any%20researcher%20within%20the%20social%20sciences.%22%2C%22date%22%3A%22January%201%2C%202013%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%2210.1080%5C%2F17405629.2012.732719%22%2C%22ISSN%22%3A%221740-5629%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F17405629.2012.732719%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T19%3A54%3A11Z%22%7D%7D%2C%7B%22key%22%3A%22F3JF7BWN%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Lin%20et%20al.%22%2C%22parsedDate%22%3A%222017-11-02%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BLin%2C%20L.-C.%2C%20Huang%2C%20P.-H.%2C%20%26amp%3B%20Weng%2C%20L.-J.%20%282017%29.%20Selecting%20Path%20Models%20in%20SEM%3A%20A%20Comparison%20of%20Model%20Selection%20Criteria.%20%26lt%3Bi%26gt%3BStructural%20Equation%20Modeling%3A%20A%20Multidisciplinary%20Journal%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B24%26lt%3B%5C%2Fi%26gt%3B%286%29%2C%20855%26%23x2013%3B869.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2017.1363652%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2017.1363652%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Selecting%20Path%20Models%20in%20SEM%3A%20A%20Comparison%20of%20Model%20Selection%20Criteria%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Li-Chung%22%2C%22lastName%22%3A%22Lin%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Po-Hsien%22%2C%22lastName%22%3A%22Huang%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Li-Jen%22%2C%22lastName%22%3A%22Weng%22%7D%5D%2C%22abstractNote%22%3A%22Model%20comparison%20is%20one%20useful%20approach%20in%20applications%20of%20structural%20equation%20modeling.%20Akaike%5Cu2019s%20information%20criterion%20%28AIC%29%20and%20the%20Bayesian%20information%20criterion%20%28BIC%29%20are%20commonly%20used%20for%20selecting%20an%20optimal%20model%20from%20the%20alternatives.%20We%20conducted%20a%20comprehensive%20evaluation%20of%20various%20model%20selection%20criteria%2C%20including%20AIC%2C%20BIC%2C%20and%20their%20extensions%2C%20in%20selecting%20an%20optimal%20path%20model%20under%20a%20wide%20range%20of%20conditions%20over%20different%20compositions%20of%20candidate%20set%2C%20distinct%20values%20of%20misspecified%20parameters%2C%20and%20diverse%20sample%20sizes.%20The%20chance%20of%20selecting%20an%20optimal%20model%20rose%20as%20the%20values%20of%20misspecified%20parameters%20and%20sample%20sizes%20increased.%20The%20relative%20performance%20of%20AIC%20and%20BIC%20type%20criteria%20depended%20on%20the%20magnitudes%20of%20the%20parameter%20misspecified.%20The%20BIC%20family%20in%20general%20outperformed%20AIC%20counterparts%20unless%20under%20small%20values%20of%20omitted%20parameters%20and%20sample%20sizes%2C%20where%20AIC%20performed%20better.%20Scaled%20unit%20information%20prior%20BIC%20%28SPBIC%29%20and%20Haughton%26%23039%3Bs%20BIC%20%28HBIC%29%20demonstrated%20the%20highest%20accuracy%20ratios%20across%20most%20of%20the%20conditions%20investigated%20in%20this%20simulation.%22%2C%22date%22%3A%22November%202%2C%202017%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%2210.1080%5C%2F10705511.2017.1363652%22%2C%22ISSN%22%3A%221070-5511%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F10705511.2017.1363652%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T19%3A53%3A22Z%22%7D%7D%2C%7B%22key%22%3A%229T334T5X%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Shi%20et%20al.%22%2C%22parsedDate%22%3A%222017-07-04%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BShi%2C%20D.%2C%20Song%2C%20H.%2C%20Liao%2C%20X.%2C%20Terry%2C%20R.%2C%20%26amp%3B%20Snyder%2C%20L.%20A.%20%282017%29.%20Bayesian%20SEM%20for%20Specification%20Search%20Problems%20in%20Testing%20Factorial%20Invariance.%20%26lt%3Bi%26gt%3BMultivariate%20Behavioral%20Research%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B52%26lt%3B%5C%2Fi%26gt%3B%284%29%2C%20430%26%23x2013%3B444.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F00273171.2017.1306432%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F00273171.2017.1306432%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Bayesian%20SEM%20for%20Specification%20Search%20Problems%20in%20Testing%20Factorial%20Invariance%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Dexin%22%2C%22lastName%22%3A%22Shi%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Hairong%22%2C%22lastName%22%3A%22Song%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Xiaolan%22%2C%22lastName%22%3A%22Liao%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Robert%22%2C%22lastName%22%3A%22Terry%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Lori%20A.%22%2C%22lastName%22%3A%22Snyder%22%7D%5D%2C%22abstractNote%22%3A%22Specification%20search%20problems%20refer%20to%20two%20important%20but%20under-addressed%20issues%20in%20testing%20for%20factorial%20invariance%3A%20how%20to%20select%20proper%20reference%20indicators%20and%20how%20to%20locate%20specific%20non-invariant%20parameters.%20In%20this%20study%2C%20we%20propose%20a%20two-step%20procedure%20to%20solve%20these%20issues.%20Step%201%20is%20to%20identify%20a%20proper%20reference%20indicator%20using%20the%20Bayesian%20structural%20equation%20modeling%20approach.%20An%20item%20is%20selected%20if%20it%20is%20associated%20with%20the%20highest%20likelihood%20to%20be%20invariant%20across%20groups.%20Step%202%20is%20to%20locate%20specific%20non-invariant%20parameters%2C%20given%20that%20a%20proper%20reference%20indicator%20has%20already%20been%20selected%20in%20Step%201.%20A%20series%20of%20simulation%20analyses%20show%20that%20the%20proposed%20method%20performs%20well%20under%20a%20variety%20of%20data%20conditions%2C%20and%20optimal%20performance%20is%20observed%20under%20conditions%20of%20large%20magnitude%20of%20non-invariance%2C%20low%20proportion%20of%20non-invariance%2C%20and%20large%20sample%20sizes.%20We%20also%20provide%20an%20empirical%20example%20to%20demonstrate%20the%20specific%20procedures%20to%20implement%20the%20proposed%20method%20in%20applied%20research.%20The%20importance%20and%20influences%20are%20discussed%20regarding%20the%20choices%20of%20informative%20priors%20with%20zero%20mean%20and%20small%20variances.%20Extensions%20and%20limitations%20are%20also%20pointed%20out.%22%2C%22date%22%3A%22July%204%2C%202017%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%2210.1080%5C%2F00273171.2017.1306432%22%2C%22ISSN%22%3A%220027-3171%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1080%5C%2F00273171.2017.1306432%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T19%3A50%3A16Z%22%7D%7D%2C%7B%22key%22%3A%22D47HQL6X%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Matsueda%22%2C%22parsedDate%22%3A%222012%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BMatsueda%2C%20R.%20L.%20%282012%29.%20Key%20advances%20in%20the%20history%20of%20structural%20equation%20modeling.%20In%20%26lt%3Bi%26gt%3BHandbook%20of%20structural%20equation%20modeling%26lt%3B%5C%2Fi%26gt%3B%20%28pp.%2017%26%23x2013%3B42%29.%20New%20York%2C%20NY%2C%20US%3A%20The%20Guilford%20Press.%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22bookSection%22%2C%22title%22%3A%22Key%20advances%20in%20the%20history%20of%20structural%20equation%20modeling%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Ross%20L.%22%2C%22lastName%22%3A%22Matsueda%22%7D%5D%2C%22abstractNote%22%3A%22In%20this%20chapter%2C%20I%20trace%20the%20key%20advances%20in%20the%20history%20of%20structural%20equation%20modeling%20%28SEM%29.%20I%20focus%20on%20the%20early%20history%20and%20try%20to%20convey%20the%20excitement%20of%20major%20developments%20in%20each%20discipline%2C%20culminating%20with%20cross-disciplinary%20integration%20in%20the%201970s.%20I%20then%20discuss%20advances%20in%20estimating%20models%20from%20data%20that%20depart%20from%20the%20usual%20assumptions%20of%20linearity%2C%20normality%2C%20and%20continuous%20distributions.%20I%20conclude%20with%20brief%20treatments%20of%20more%20recent%20advances%20to%20provide%20introductions%20to%20advanced%20chapters%20in%20this%20volume.%20%28PsycINFO%20Database%20Record%20%28c%29%202019%20APA%2C%20all%20rights%20reserved%29%22%2C%22bookTitle%22%3A%22Handbook%20of%20structural%20equation%20modeling%22%2C%22date%22%3A%222012%22%2C%22language%22%3A%22%22%2C%22ISBN%22%3A%22978-1-60623-077-0%20978-1-4625-0447-3%22%2C%22url%22%3A%22%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T19%3A21%3A59Z%22%7D%7D%2C%7B%22key%22%3A%22UBX37JAK%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Bollen%22%2C%22parsedDate%22%3A%222005%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BBollen%2C%20K.%20A.%20%282005%29.%20Structural%20Equation%20Models.%20In%20%26lt%3Bi%26gt%3BEncyclopedia%20of%20Biostatistics%26lt%3B%5C%2Fi%26gt%3B.%20American%20Cancer%20Society.%20https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1002%5C%2F0470011815.b2a13089%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22bookSection%22%2C%22title%22%3A%22Structural%20Equation%20Models%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Kenneth%20A.%22%2C%22lastName%22%3A%22Bollen%22%7D%5D%2C%22abstractNote%22%3A%22Structural%20equation%20models%20refer%20to%20general%20statistical%20procedures%20for%20multiequation%20systems%20that%20include%20continuous%20latent%20variables%2C%20multiple%20indicators%20of%20concepts%2C%20errors%20of%20measurement%2C%20errors%20in%20equations%2C%20and%20observed%20variables.%20An%20analysis%20that%20uses%20structural%20equation%20models%20has%20several%20components.%20These%20include%20%28a%29%20model%20specification%2C%20%28b%29%20the%20implied%20moment%20matrix%2C%20%28c%29%20identification%2C%20%28d%29%20estimation%2C%20%28e%29%20model%20fit%2C%20and%20%28f%29%20respecification.%20Historical%20origins%20of%20structural%20equation%20models%20are%20also%20described.%22%2C%22bookTitle%22%3A%22Encyclopedia%20of%20Biostatistics%22%2C%22date%22%3A%222005%22%2C%22language%22%3A%22en%22%2C%22ISBN%22%3A%22978-0-470-01181-2%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fonlinelibrary.wiley.com%5C%2Fdoi%5C%2Fabs%5C%2F10.1002%5C%2F0470011815.b2a13089%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T17%3A53%3A41Z%22%7D%7D%2C%7B%22key%22%3A%222RD2GRHX%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Tarka%22%2C%22parsedDate%22%3A%222018-01-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BTarka%2C%20P.%20%282018%29.%20An%20overview%20of%20structural%20equation%20modeling%3A%20its%20beginnings%2C%20historical%20development%2C%20usefulness%20and%20controversies%20in%20the%20social%20sciences.%20%26lt%3Bi%26gt%3BQuality%20%26amp%3B%20Quantity%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B52%26lt%3B%5C%2Fi%26gt%3B%281%29%2C%20313%26%23x2013%3B354.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs11135-017-0469-8%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs11135-017-0469-8%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22An%20overview%20of%20structural%20equation%20modeling%3A%20its%20beginnings%2C%20historical%20development%2C%20usefulness%20and%20controversies%20in%20the%20social%20sciences%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Piotr%22%2C%22lastName%22%3A%22Tarka%22%7D%5D%2C%22abstractNote%22%3A%22This%20paper%20is%20a%20tribute%20to%20researchers%20who%20have%20significantly%20contributed%20to%20improving%20and%20advancing%20structural%20equation%20modeling%20%28SEM%29.%20It%20is%2C%20therefore%2C%20a%20brief%20overview%20of%20SEM%20and%20presents%20its%20beginnings%2C%20historical%20development%2C%20its%20usefulness%20in%20the%20social%20sciences%20and%20the%20statistical%20and%20philosophical%20%28theoretical%29%20controversies%20which%20have%20often%20appeared%20in%20the%20literature%20pertaining%20to%20SEM.%20Having%20described%20the%20essence%20of%20SEM%20in%20the%20context%20of%20causal%20analysis%2C%20the%20author%20discusses%20the%20years%20of%20the%20development%20of%20structural%20modeling%20as%20the%20consequence%20of%20many%20researchers%5Cu2019%20systematically%20growing%20needs%20%28in%20particular%20in%20the%20social%20sciences%29%20who%20strove%20to%20effectively%20understand%20the%20structure%20and%20interactions%20of%20latent%20phenomena.%20The%20early%20beginnings%20of%20SEM%20models%20were%20related%20to%20the%20work%20of%20Spearman%20and%20Wright%2C%20and%20to%20that%20of%20other%20prominent%20researchers%20who%20contributed%20to%20SEM%20development.%20The%20importance%20and%20predominance%20of%20theoretical%20assumptions%20over%20technical%20issues%20for%20the%20successful%20construction%20of%20SEM%20models%20are%20also%20described.%20Then%2C%20controversies%20regarding%20the%20use%20of%20SEM%20in%20the%20social%20sciences%20are%20presented.%20Finally%2C%20the%20opportunities%20and%20threats%20of%20this%20type%20of%20analytical%20strategy%20as%20well%20as%20selected%20areas%20of%20SEM%20applications%20in%20the%20social%20sciences%20are%20discussed.%22%2C%22date%22%3A%222018-01-01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1007%5C%2Fs11135-017-0469-8%22%2C%22ISSN%22%3A%221573-7845%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs11135-017-0469-8%22%2C%22collections%22%3A%5B%22QMFX7H5V%22%5D%2C%22dateModified%22%3A%222020-05-26T17%3A52%3A20Z%22%7D%7D%2C%7B%22key%22%3A%22L8YMREKE%22%2C%22library%22%3A%7B%22id%22%3A881472%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Sewell%20and%20Stallman%22%2C%22parsedDate%22%3A%222020-06-01%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%26lt%3Bdiv%20class%3D%26quot%3Bcsl-bib-body%26quot%3B%20style%3D%26quot%3Bline-height%3A%202%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%26quot%3B%26gt%3B%5Cn%20%20%26lt%3Bdiv%20class%3D%26quot%3Bcsl-entry%26quot%3B%26gt%3BSewell%2C%20D.%20K.%2C%20%26amp%3B%20Stallman%2C%20A.%20%282020%29.%20Modeling%20the%20Effect%20of%20Speed%20Emphasis%20in%20Probabilistic%20Category%20Learning.%20%26lt%3Bi%26gt%3BComputational%20Brain%20%26amp%3B%20Behavior%26lt%3B%5C%2Fi%26gt%3B%2C%20%26lt%3Bi%26gt%3B3%26lt%3B%5C%2Fi%26gt%3B%282%29%2C%20129%26%23x2013%3B152.%20%26lt%3Ba%20class%3D%26%23039%3Bzp-ItemURL%26%23039%3B%20href%3D%26%23039%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-019-00067-6%26%23039%3B%26gt%3Bhttps%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-019-00067-6%26lt%3B%5C%2Fa%26gt%3B%26lt%3B%5C%2Fdiv%26gt%3B%5Cn%26lt%3B%5C%2Fdiv%26gt%3B%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Modeling%20the%20Effect%20of%20Speed%20Emphasis%20in%20Probabilistic%20Category%20Learning%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22David%20K.%22%2C%22lastName%22%3A%22Sewell%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Alexander%22%2C%22lastName%22%3A%22Stallman%22%7D%5D%2C%22abstractNote%22%3A%22For%20many%20decisions%20in%20life%2C%20there%20is%20uncertainty%20about%20the%20outcome%20even%20if%20the%20stimulus%20is%20a%20familiar%20one.%20Under%20these%20circumstances%2C%20people%20often%20rely%20upon%20previous%20experience%20to%20make%20a%20choice.%20In%20general%2C%20more%20accurate%20responding%20is%20achieved%20when%20one%20considers%20decision-relevant%20information%20for%20longer.%20There%20are%20practical%20limits%2C%20however%2C%20to%20how%20long%20one%20can%20deliberate%2C%20and%20so%20decision-makers%20must%20balance%20decision%20speed%20against%20accuracy.%20Traditionally%2C%20the%20overall%20speed%20with%20which%20people%20respond%20has%20been%20understood%20in%20terms%20of%20changes%20in%20the%20evidence%20threshold%20used%20for%20decision-making.%20However%2C%20more%20recent%20findings%20suggest%20that%20speed%20pressure%20may%20also%20affect%20the%20quality%20of%20information%20people%20recruit%20for%20making%20decisions.%20The%20current%20study%20investigated%20the%20effects%20of%20emphasizing%20either%20response%20speed%20or%20response%20accuracy%20on%20decision-making%20in%20a%20probabilistic%20category%20learning%20task.%20Strikingly%2C%20conclusions%20from%20two%20model-based%20analyses%20of%20performance%20depended%20on%20whether%20data%20were%20analyzed%20at%20the%20level%20of%20individuals%20or%20the%20group%20average.%20For%20the%20group-level%20analyses%2C%20speed%20pressure%20selectively%20influenced%20evidence%20threshold.%20For%20the%20individual-level%20analyses%2C%20speed%20pressure%20affected%20both%20evidence%20threshold%20as%20well%20as%20the%20quality%20of%20information%20driving%20decision-making%20for%20four%20out%20of%20six%20participants.%20Our%20findings%20are%20consistent%20with%20recent%20results%20that%20identify%20common%20brain%20areas%20associated%20with%20setting%20evidence%20thresholds%20decision-making%20and%20representing%20category-level%20information%20in%20trial-by-trial%20associative%20learning.%22%2C%22date%22%3A%222020-06-01%22%2C%22language%22%3A%22en%22%2C%22DOI%22%3A%2210.1007%5C%2Fs42113-019-00067-6%22%2C%22ISSN%22%3A%222522-087X%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fdoi.org%5C%2F10.1007%5C%2Fs42113-019-00067-6%22%2C%22collections%22%3A%5B%22IFJ5FWUK%22%5D%2C%22dateModified%22%3A%222020-05-26T07%3A48%3A26Z%22%7D%7D%5D%7D
Baumann, C., Singmann, H., Gershman, S. J., & Helversen, B. von. (2020). A linear threshold model for optimal stopping behavior.
Proceedings of the National Academy of Sciences,
117(23), 12750–12755.
https://doi.org/10.1073/pnas.2002312117
Merkle, E. C., & Wang, T. (2018). Bayesian latent variable models for the analysis of experimental psychology data.
Psychonomic Bulletin & Review,
25(1), 256–270.
https://doi.org/10.3758/s13423-016-1016-7
Overstall, A. M., & Forster, J. J. (2010). Default Bayesian model determination methods for generalised linear mixed models.
Computational Statistics & Data Analysis,
54(12), 3269–3288.
https://doi.org/10.1016/j.csda.2010.03.008
Llorente, F., Martino, L., Delgado, D., & Lopez-Santiago, J. (2020). Marginal likelihood computation for model selection and hypothesis testing: an extensive review.
ArXiv:2005.08334 [Cs, Stat]. Retrieved from
http://arxiv.org/abs/2005.08334
Duersch, P., Lambrecht, M., & Oechssler, J. (2020). Measuring skill and chance in games.
European Economic Review,
127, 103472.
https://doi.org/10.1016/j.euroecorev.2020.103472
Lee, M. D., & Courey, K. A. (2020). Modeling Optimal Stopping in Changing Environments: a Case Study in Mate Selection.
Computational Brain & Behavior.
https://doi.org/10.1007/s42113-020-00085-9
Xie, W., Bainbridge, W. A., Inati, S. K., Baker, C. I., & Zaghloul, K. A. (2020). Memorability of words in arbitrary verbal associations modulates memory retrieval in the anterior temporal lobe.
Nature Human Behaviour.
https://doi.org/10.1038/s41562-020-0901-2
Greenland, S., Madure, M., Schlesselman, J. J., Poole, C., & Morgenstern, H. (2020). Standardized Regression Coefficients: A Further Critique and Review of Some Alternatives, 7.
Gelman, A. (2020, June 22). Retraction of racial essentialist article that appeared in Psychological Science « Statistical Modeling, Causal Inference, and Social Science. Retrieved June 24, 2020, from
https://statmodeling.stat.columbia.edu/2020/06/22/retraction-of-racial-essentialist-article-that-appeared-in-psychological-science/
Rozeboom, W. W. (1970). 2. The Art of Metascience, or, What Should a Psychological Theory Be? In J. Royce (Ed.), Toward Unification in Psychology (pp. 53–164). Toronto: University of Toronto Press. https://doi.org/10.3138/9781487577506-003
Gneiting, T., & Raftery, A. E. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation.
Journal of the American Statistical Association,
102(477), 359–378.
https://doi.org/10.1198/016214506000001437
Rouhani, N., Norman, K. A., Niv, Y., & Bornstein, A. M. (2020). Reward prediction errors create event boundaries in memory.
Cognition,
203, 104269.
https://doi.org/10.1016/j.cognition.2020.104269
Robinson, M. M., Benjamin, A. S., & Irwin, D. E. (2020). Is there a K in capacity? Assessing the structure of visual short-term memory.
Cognitive Psychology,
121, 101305.
https://doi.org/10.1016/j.cogpsych.2020.101305
Lee, M. D., Criss, A. H., Devezer, B., Donkin, C., Etz, A., Leite, F. P., … Vandekerckhove, J. (2019). Robust Modeling in Cognitive Science.
Computational Brain & Behavior,
2(3), 141–153.
https://doi.org/10.1007/s42113-019-00029-y
Bailer-Jones, D. (2009). Scientific models in philosophy of science. Pittsburgh, Pa.,: University of Pittsburgh Press.
Suppes, P. (2002). Representation and invariance of scientific structures. Stanford, Calif.: CSLI Publications.
Roy, D. (2003). The Discrete Normal Distribution.
Communications in Statistics - Theory and Methods,
32(10), 1871–1883.
https://doi.org/10.1081/STA-120023256
Ospina, R., & Ferrari, S. L. P. (2012). A general class of zero-or-one inflated beta regression models.
Computational Statistics & Data Analysis,
56(6), 1609–1623.
https://doi.org/10.1016/j.csda.2011.10.005
Uygun Tunç, D., & Tunç, M. N. (2020). A Falsificationist Treatment of Auxiliary Hypotheses in Social and Behavioral Sciences: Systematic Replications Framework (preprint). PsyArXiv. https://doi.org/10.31234/osf.io/pdm7y
Murayama, K., Blake, A. B., Kerr, T., & Castel, A. D. (2016). When enough is not enough: Information overload and metacognitive decisions to stop studying information.
Journal of Experimental Psychology: Learning, Memory, and Cognition,
42(6), 914–924.
https://doi.org/10.1037/xlm0000213
Jefferys, W. H., & Berger, J. O. (1992). Ockham’s Razor and Bayesian Analysis.
American Scientist,
80(1), 64–72. Retrieved from
https://www.jstor.org/stable/29774559
Maier, S. U., Raja Beharelle, A., Polanía, R., Ruff, C. C., & Hare, T. A. (2020). Dissociable mechanisms govern when and how strongly reward attributes affect decisions.
Nature Human Behaviour.
https://doi.org/10.1038/s41562-020-0893-y
Nadarajah, S. (2009). An alternative inverse Gaussian distribution.
Mathematics and Computers in Simulation,
79(5), 1721–1729.
https://doi.org/10.1016/j.matcom.2008.08.013
Barndorff-Nielsen, O., BlÆsild, P., & Halgreen, C. (1978). First hitting time models for the generalized inverse Gaussian distribution.
Stochastic Processes and Their Applications,
7(1), 49–54.
https://doi.org/10.1016/0304-4149(78)90036-4
Ghitany, M. E., Mazucheli, J., Menezes, A. F. B., & Alqallaf, F. (2019). The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval.
Communications in Statistics - Theory and Methods,
48(14), 3423–3438.
https://doi.org/10.1080/03610926.2018.1476717
Weichart, E. R., Turner, B. M., & Sederberg, P. B. (2020). A model of dynamic, within-trial conflict resolution for decision making.
Psychological Review.
https://doi.org/10.1037/rev0000191
Bates, C. J., & Jacobs, R. A. (2020). Efficient data compression in perception and perceptual memory.
Psychological Review.
https://doi.org/10.1037/rev0000197
Kvam, P. D., & Busemeyer, J. R. (2020). A distributional and dynamic theory of pricing and preference.
Psychological Review.
https://doi.org/10.1037/rev0000215
Blundell, C., Sanborn, A., & Griffiths, T. L. (2012). Look-Ahead Monte Carlo with People (p. 7). Presented at the Proceedings of the Annual Meeting of the Cognitive Science Society.
Leon-Villagra, P., Otsubo, K., Lucas, C. G., & Buchsbaum, D. (2020). Uncovering Category Representations with Linked MCMC with people. In Proceedings of the Annual Meeting of the Cognitive Science Society (p. 7).
Leon-Villagra, P., Klar, V. S., Sanborn, A. N., & Lucas, C. G. (2019). Exploring the Representation of Linear Functions. In Proceedings of the Annual Meeting of the Cognitive Science Society (p. 7).
Ramlee, F., Sanborn, A. N., & Tang, N. K. Y. (2017). What Sways People’s Judgment of Sleep Quality? A Quantitative Choice-Making Study With Good and Poor Sleepers.
Sleep,
40(7).
https://doi.org/10.1093/sleep/zsx091
Hsu, A. S., Martin, J. B., Sanborn, A. N., & Griffiths, T. L. (2019). Identifying category representations for complex stimuli using discrete Markov chain Monte Carlo with people.
Behavior Research Methods,
51(4), 1706–1716.
https://doi.org/10.3758/s13428-019-01201-9
Martin, J. B., Griffiths, T. L., & Sanborn, A. N. (2012). Testing the Efficiency of Markov Chain Monte Carlo With People Using Facial Affect Categories.
Cognitive Science,
36(1), 150–162.
https://doi.org/10.1111/j.1551-6709.2011.01204.x
Gronau, Q. F., Wagenmakers, E.-J., Heck, D. W., & Matzke, D. (2019). A Simple Method for Comparing Complex Models: Bayesian Model Comparison for Hierarchical Multinomial Processing Tree Models Using Warp-III Bridge Sampling.
Psychometrika,
84(1), 261–284.
https://doi.org/10.1007/s11336-018-9648-3
Wickelmaier, F., & Zeileis, A. (2018). Using recursive partitioning to account for parameter heterogeneity in multinomial processing tree models.
Behavior Research Methods,
50(3), 1217–1233.
https://doi.org/10.3758/s13428-017-0937-z
Jacobucci, R., & Grimm, K. J. (2018). Comparison of Frequentist and Bayesian Regularization in Structural Equation Modeling.
Structural Equation Modeling: A Multidisciplinary Journal,
25(4), 639–649.
https://doi.org/10.1080/10705511.2017.1410822
Raftery, A. E. (1993). Bayesian model selection in structural equation models. In K. A. Bollen & J. S. Long (Eds.), Testing Structural Equation Models (pp. 163–180). Beverly Hills: SAGE Publications.
Lewis, S. M., & Raftery, A. E. (1997). Estimating Bayes Factors via Posterior Simulation With the Laplace-Metropolis Estimator.
Journal of the American Statistical Association,
92(438), 648–655.
https://doi.org/10.2307/2965712
Mair, P. (2018). Modern psychometrics with R. Cham, Switzerland: Springer.
Rosseel, Y. (2012). lavaan: An R Package for Structural Equation Modeling.
Journal of Statistical Software,
48(1), 1–36.
https://doi.org/10.18637/jss.v048.i02
Kaplan, D., & Lee, C. (2016). Bayesian Model Averaging Over Directed Acyclic Graphs With Implications for the Predictive Performance of Structural Equation Models.
Structural Equation Modeling: A Multidisciplinary Journal,
23(3), 343–353.
https://doi.org/10.1080/10705511.2015.1092088
Schoot, R. van de, Verhoeven, M., & Hoijtink, H. (2013). Bayesian evaluation of informative hypotheses in SEM using Mplus: A black bear story.
European Journal of Developmental Psychology,
10(1), 81–98.
https://doi.org/10.1080/17405629.2012.732719
Lin, L.-C., Huang, P.-H., & Weng, L.-J. (2017). Selecting Path Models in SEM: A Comparison of Model Selection Criteria.
Structural Equation Modeling: A Multidisciplinary Journal,
24(6), 855–869.
https://doi.org/10.1080/10705511.2017.1363652
Shi, D., Song, H., Liao, X., Terry, R., & Snyder, L. A. (2017). Bayesian SEM for Specification Search Problems in Testing Factorial Invariance.
Multivariate Behavioral Research,
52(4), 430–444.
https://doi.org/10.1080/00273171.2017.1306432
Matsueda, R. L. (2012). Key advances in the history of structural equation modeling. In Handbook of structural equation modeling (pp. 17–42). New York, NY, US: The Guilford Press.
Bollen, K. A. (2005). Structural Equation Models. In Encyclopedia of Biostatistics. American Cancer Society. https://doi.org/10.1002/0470011815.b2a13089
Tarka, P. (2018). An overview of structural equation modeling: its beginnings, historical development, usefulness and controversies in the social sciences.
Quality & Quantity,
52(1), 313–354.
https://doi.org/10.1007/s11135-017-0469-8
Sewell, D. K., & Stallman, A. (2020). Modeling the Effect of Speed Emphasis in Probabilistic Category Learning.
Computational Brain & Behavior,
3(2), 129–152.
https://doi.org/10.1007/s42113-019-00067-6
Related
[…] second part shows how to perform model diagnostics and how to asses the model fit. The third part shows how to test for differences in parameters between […]
[…] between parameters as a function of the speed-accuracy condition. This is the topic of the third blog post. I am hopeful it will not take two months this […]